Concept#
This section details the linear regression model from a probabilistic perspective.
Intuition#
As a running example, suppose that we wish to estimate the prices of houses (in dollars) based on their area (in square feet) and age (in years). To develop a model for predicting house prices, we need to get our hands on data consisting of sales, including the sales price, area, and age for each home. In the terminology of machine learning, the dataset is called a training dataset or training set, and each row (containing the data corresponding to one sale) is called an example (or data point, instance, sample). The thing we are trying to predict (price) is called a label (or target). The variables (age and area) upon which the predictions are based are called features (or covariates) [Zhang et al., 2023].
Let’s create a housing dataset below with \(100\) samples.
| House Size (sqft) | Age (years) | Price ($) | |
|---|---|---|---|
| 0 | 51 | 25 | 163551 |
| 1 | 92 | 24 | 201654 |
| 2 | 14 | 44 | 121846 |
| 3 | 71 | 40 | 186793 |
| 4 | 60 | 28 | 170572 |
| ... | ... | ... | ... |
| 95 | 84 | 0 | 171542 |
| 96 | 79 | 26 | 193731 |
| 97 | 81 | 12 | 190853 |
| 98 | 52 | 40 | 163161 |
| 99 | 23 | 2 | 125537 |
100 rows × 3 columns
The goal is to predict the price of a house given its size. We can visualize the relationship between the house size and the price using a scatter plot.
Show code cell source
1X = data['House Size (sqft)']
2y = data['Price ($)']
3
4plt.scatter(X, y)
5plt.xlabel('House Size (sqft)')
6plt.ylabel('Price ($)')
7plt.show()

Univariate Linear Model#
Let’s try to model the relationship between the house size (sqft) and the price ($). The assumption of linearity means that the expected value of the target (price) can be expressed as a linear function of the feature (sqft).
where \(\beta_0\) is the intercept, \(\beta_1\) the coefficient, \(x\) the feature (sqft) and \(y\) the target (price).
Here the coefficient \(\beta_1\) is called the weights and the intercept \(\beta_0\) is called the bias.
The weights determine the influence of each feature on our prediction, this means that a larger weight indicates that the feature is more important for predicting the target.
The bias determines the value of the estimate when all features are zero. Why do we need this? Will there ever be a case where the house size (sqft) is \(0\)? No, but we still need the bias because it allows us to express the functional/hypothesis space of linear functions (more on that later). Intuitively, if there is no bias, the equation will always pass through the origin, which means that the model can never vary up or down.
Remark 35 (Why do we need a bias?)
If there is no bias term in the model, you will lose the flexibility of your model. Imagine a simple linear regression model without a bias term, then your linear equation \(y=mx\) will only pass through the origin. Therefore, if your underlying data (pretend that we know that the underlying data’s actual function \(y = 3x + 5\)), then your Linear Regression model will never find the “best fit line” simply because we already assume that our prediction is governed by the slope \(m\), and there does not exist our \(c\), the intercept/bias term.
Therefore, it is usually the case whereby we always add in an intercept term. We intend to estimate the values of \(y\) given \(x\). Each value of \(x\) is multiplied by \(\beta_{1}\), with a constant intercept term \(\beta_{0}\). We also note that \(1\) unit increase in \(x\) will correspond to a \(\beta_1\) unit increase in \(y\) according to the model, while always remebering to add the intercept term.
The equation (125) is an affine transformation of the input features. The difference between an affine transformation and a linear transformation is that an affine transformation has a translation (bias) component. In other words, an affine transformation is a linear transformation combined with a translation.
Our goal is to choose the weights \(\beta_1\) and the bias \(\beta_0\) such that, on average, make our model’s predictions fit the true prices observed in the data as closely as possible [Zhang et al., 2023]. This also means being able to extrapolate to new data points that were not part of the training set.
For example, the best fit line for the data above is shown below.
Show code cell source
1X = data['House Size (sqft)']
2y = data['Price ($)']
3
4plt.scatter(X, y)
5plt.plot(np.unique(X), np.poly1d(np.polyfit(X, y, 1))(np.unique(X)), color='red')
6plt.xlabel('House Size (sqft)')
7plt.ylabel('Price ($)')
8plt.show()

Our goal is to find that red line among all possible lines that best fits the data.
Multivariate Linear Model#
It is often the case that there are multiple explanatory variables (features). As a continuation of the example above, let’s say that we want to predict the price of a house given its size and age, we would then have the linear equation below.
where \(\beta_0\) is the intercept, \(\beta_1\) and \(\beta_2\) the coefficients, \(x_1\) and \(x_2\) the features (sqft and age) and \(y\) the target (price).
Then our task is to find the best values for the weights \(\beta_1\) and \(\beta_2\) and the bias \(\beta_0\) such that the model’s predictions are as close as possible to the true prices observed in the data.
The Hypothesis Space#
As with any machine learning problem, we need to define a hypothesis space \(\mathcal{H}\), which is the set of all possible models that we consider. In the case of linear regression, the hypothesis space is the set of all possible linear functions.
where we specify
\(\mathbf{x} \in \mathbb{R}^{D}\) is the input vector,
\(\boldsymbol{\beta} \in \mathbb{R}^{D}\) is the weight vector,
\(\beta_0 \in \mathbb{R}\) is the bias,
\(h\) as a function of \(\mathbf{x}\) and \(\boldsymbol{\beta}\), and we put \(\boldsymbol{\beta}\) after \(;\) to indicate that \(h\) is parameterized by \(\boldsymbol{\beta}\).
We will explain them in more detail in the next few sections.
The Loss Function#
Once we have defined our hypothesis, we need to define a loss function \(\mathcal{L}\) that measures how good a given hypothesis \(h\) is.
The loss in the case of linear regression is usually the mean squared error loss (MSE), which we will use in this section.
and via the ERM framework we deal with empirical loss \(\widehat{\mathcal{L}}\) which we will make precise later.
Problem Formulation#
The main formulation is formulated based on Foundations of Machine Learning [Mohri and Ameet, 2018].
Consider \(\mathcal{X}\) as our input space, usually \(\mathbb{R}^{D}\), and \(\mathcal{Y}\) a measurable subset of \(\mathbb{R}\), we adopt the probablistic framework and denote \(\mathbb{P}_{\mathcal{D}}\) as the probability distribution over \(\mathcal{X} \times \mathcal{Y}\). The deterministic scenario is merely a special case where \(\mathbb{P}_{\mathcal{D}}\) is a Dirac delta function[1], and that we have a ground truth function \(f: \mathcal{X} \rightarrow \mathcal{Y}\) that uniquely determines the target \(y \in \mathcal{Y}\) for any input \(\mathbf{x} \in \mathcal{X}\).
Then the linear regression model has the following form:
where
\(\varepsilon\) is a random variable drawn \(i.i.d.\) from a zero-mean Gaussian distribution with variance \(\sigma^2\)
\(f\) is the unknown ground truth linear function of the parameters \(\boldsymbol{\beta}\).
To be more precise, the \(\varepsilon^{(1)}, \ldots, \varepsilon^{(N)}\) are all conditionally \(i.i.d.\) given \(\mathbf{x}^{(1)}, \ldots, \mathbf{x}^{(N)}\):
It follows that (explained later) that we can interpret \(y\) as a realization of a random variable \(Y\):
and whether \(Y\) is indeed \(i.i.d.\) depends on if we treat \(\mathbf{x}\) as a realization of a random variable \(\mathbf{X}\) or not.
In any case, we are interested in finding \(y \mid \mathbf{x}\), so we can also say that:
which we will show later.
Our goal is to learn a linear hypothesis \(h\) that approximates \(f\) as closely as possible, both in terms of the generalization error and the training error. In other words, we want to find a good estimate \(\hat{h}\) of the ground truth function \(f\) in (127) such that the error between \(\hat{h}\) and \(f\) is small.
As in all supervised learning problems, the learner \(\mathcal{A}\) receives a labeled sample dataset \(\mathcal{S}\) containing \(N\) i.i.d. samples \(\left(\mathbf{x}^{(n)}, y^{(n)}\right)\) drawn from \(\mathbb{P}_{\mathcal{D}}\):
Subsequently, the learner \(\mathcal{A}\) will learn a linear hypothesis (linear in the parameters) \(h \in \mathcal{H}\) that minimizes a certain defined loss function \(\mathcal{L}\).
Remark 36 (The i.i.d. assumption)
Something to note is that if the data points for \(\mathbf{x}\) is fixed and known, which is a common assumption in many formulations, then only the error term \(\varepsilon\) is drawn \(i.i.d.\).
More concretely, define the learned hypothesis \(\hat{h}\) to be of the following form:
where we collected all features \(x_1, \ldots, x_D\) into a vector \(\mathbf{x}\) and all weights \(\hat{\beta}_1, \ldots, \hat{\beta}_D\) into a vector \(\hat{\boldsymbol{\beta}}\). Note that the “hat” symbol is used to denote an estimated quantity.
It is also typical to add a bias term \(1\) to the input vector \(\mathbf{x}\) and a bias weight \(\hat{\beta}_0\) to the weight vector \(\hat{\boldsymbol{\beta}}\) for a more compact notation:
where
the vector \(\mathbf{x}\) is re-defined to be of the form below:
(133)#\[\begin{split} \mathbf{x} = \begin{bmatrix}1 \\ x_1 \\ \vdots \\ x_D\end{bmatrix}_{(D+1) \times 1} \end{split}\]and \(x_1, \ldots, x_D\) are the features of the input \(\mathbf{x}\) and \(1\) is the bias term.
the weight vector \(\boldsymbol{\beta}\) is re-defined to be of the form below:
(134)#\[\begin{split} \boldsymbol{\beta} = \begin{bmatrix}\beta_0 \\ \beta_1 \\ \vdots \\ \beta_D\end{bmatrix}_{(D+1) \times 1} \end{split}\]where \(\beta_0\) is the bias term and \(\beta_1, \ldots, \beta_D\) are the weights of the features \(x_1, \ldots, x_D\).
Next, we define a loss function \(\mathcal{L}\) that measures the error between the true label \(y\) and the predicted label \(\hat{h}\left(\mathbf{x}; \boldsymbol{\beta}\right)\).
We present a few equivalent notations for the loss function \(\mathcal{L}\):
where the last equation is to emphasize that the loss function \(\mathcal{L}\) is a function of the weight vector \(\hat{\boldsymbol{\beta}}\) and not of the input \(\mathbf{x}\) for the context of machine learning.
The choice of loss function in regression is often the mean squared error loss (MSE) defined by:
where we used the fact that \(\hat{y} = \hat{\boldsymbol{\beta}}^T \mathbf{x}\).
One should not be surprised that we use such a loss function, as compared to other loss functions such as cross-entropy loss or zero-one loss in classification. This is because the label \(y\) in regression is a real-valued number and we are not measuring the error in terms of the equality or inequality of the predicted label \(\hat{y}\) and the true label \(y\).
To this end, we will invoke the Empirical Risk Minimization (ERM) framework mentioned in our earlier section.
Given a hypothesis set \(\mathcal{H}\) of functions mapping \(\mathcal{X}\) to \(\mathcal{Y}\), the regression problem consists of using the labeled sample \(\mathcal{S}\) (130) to find a hypothesis \(h \in \mathcal{H}\) with small expected loss or generalization error \(\mathcal{R}(\hat{h})\) with respect to the target \(f\) :
We will denote \(\mathcal{R}_{\mathcal{D}}\) as \(\mathcal{R}\) when the context is clear.
Then via the Empirical Risk Minimization (ERM) framework, we can define the empirical risk or empirical loss of \(h\) as:
It is also very common to denote the empirical risk as \(\widehat{\mathcal{R}}_{\mathcal{S}}\) as \(\widehat{\mathcal{R}}\) when the context is clear. In addition, in some machine learning texts, the empirical risk is the cost function, denoted as \(\widehat{\mathcal{J}}\).
And thus, we task a learner \(\mathcal{A}\), which can be any algorithm that takes as input the dataset \(\mathcal{S}\) that searches for the optimal parameters \(\hat{\boldsymbol{\beta}}\) that minimize the empirical risk \(\widehat{\mathcal{R}}_{\mathcal{S}}(\hat{h})\). We define the objective function as follows:
where \(\hat{h}\) is a of the form \(\hat{h}(\mathbf{x}) = \hat{\boldsymbol{\beta}}^T \mathbf{x}\).
Since the hypothesis space \(\mathcal{H}\) is parametrized by the weight vector \(\hat{\boldsymbol{\beta}}\), we can rewrite the objective function as follows:
It is worth mentioning that both (140) and (141) are equivalent in the sense that solving for the optimal \(\hat{\boldsymbol{\beta}}\) in (141) will in turn be used to construct an optimal hypothesis \(\hat{h}\) in (140) [Jung, 2023].
Example 20 (What is a learner?)
As an example, \(\mathcal{A}\) can be a linear regression algorithm (gradient descent) that minimizes the empirical risk \(\widehat{\mathcal{R}}_{\mathcal{S}}(\hat{h})\).
We have wrapped up the problem formulation, we will proceed to expand on a few details in the following sections.
The Normal Distribution, Gaussian Noise and the Mean Squared Error#
Previously, we claimed that we can interpret \(y\) as a realization of a random variable \(Y\):
But why is this the case?
Target Variable is Normally Distributed#
To see why this is the case, let’s consider the following linear regression model:
and note that we treat \(f(\cdot)\) as a deterministic function of \(\mathbf{x}\) and \(\boldsymbol{\beta}\) (see section 3.1.1 of [Bishop, 2007]). Under this assumption, then it is easy to see that \(y\) must follow a normal distribution with mean \(\beta_0 + \boldsymbol{\beta}^T \mathbf{x}\) and variance \(\sigma^2\).
This is because the only source of randomness in (143) is \(\varepsilon\), which follows a normal distribution with mean \(0\) and variance \(\sigma^2\). Then adding a constant (since it is a deterministic function) to a normal distribution with mean \(0\) and variance \(\sigma^2\) will mean shifting the mean of the Gaussian distribution by the constant and the variance remains the same.
Thus, we have:
However, we are not that interested in the distribution of \(y\) unconditioned. Why? If we model the distribution of \(y\) unconditioned, then we are essentially saying that we do not care about the input features \(\mathbf{x}\), which is not true. We are interested in the distribution of \(y\) given \(\mathbf{x}\)!
Remark 37 (Is \(\mathbf{X}\) a random variable?)
We assumed earlier that \(f(\cdot)\) is deterministic and therefore \(\mathbf{X}\) is fixed and known. So in this scenario the “randomness” is removed. How do we reconcile with our formulation that we are drawing \(i.i.d.\) samples from \(\mathcal{D}\)?
If \(\mathbf{X} = \mathbf{x}\) is assumed to be a random variable, then \(f(\cdot)\) is random as well. And there is no guarantee that the unconditional distribution of \(y\) is normal, however, we can prove instead that the conditional distribution of \(y\) given \(\mathbf{x}\) is normally distributed, which is what we are interested in.
I personally also have troubles reconciling the two formulations, but I think it requires a much more rigourous treatment of probability theory to fully understand the difference.
The Conditional Distribution of \(y\) Given \(\mathbf{x}\) is Normally Distributed#
It can be shown that the conditional distribution of \(y\) given \(\mathbf{x}\) is also normally distributed with the same vein of logic in the previous section.
That means the following:
where the notation \(\mathcal{N}\left(y ; f\left(\mathbf{x}; \boldsymbol{\beta}\right), \sigma^2\right)\) means that the distribution is a normal distribution with mean \(f\left(\mathbf{x}; \boldsymbol{\beta}\right)\) and variance \(\sigma^2\). The \(y\) is the random variable that is of interest to us. Note because we are finding the conditional of \(y\) given \(\mathbf{x}\), there is nothing random about \(\mathbf{x}\) and hence the whole PDF is of \(y\).
Then consider the expectation of \(y\) given \(\mathbf{x}\) below:
since by definition the expectation of a normal distribution is the mean parameter.
Linear regression can be interpreted as the conditional expectation of the target variable \(y\) given the features \(\mathbf{x}\). In other words, it provides an estimate of the expected value of the target variable, given a set of input features.
Consequently, finding the optimal \(\boldsymbol{\beta}\) gives rise the hypothesis \(\hat{h} = \boldsymbol{\beta}^T \mathbf{x}\), which also turns out to be the estimate of the conditional expectation of \(y\) given \(\mathbf{x}\).
Example 21 (Example: Conditional Expectation)
Say \(X\) and \(Y\) represent the height and weight of a person, respectively.
Let’s say we are given that \(X = 170\) cm, then the conditional expectation of \(Y\) given \(X = 170\) cm, denoted as \(\mathbb{E}[Y \mid X = 170]\) is the expected weight of a person with height \(170\) cm.
The inclusion of the concept of expectation is powerful! This is because it takes into account the whole population of people with height \(170\) cm, not just a single person.
Mean Squared Error estimates the Conditional Expectation#
We will prove this later, but for now, the mean squared error is an unbiased estimator of the conditional expectation of \(y\) given \(\mathbf{x}\).
See section 3.1.1. of [Bishop, 2007] for more details.
Linear in Parameters#
One confusion that often arises is that linear regression defined in (143) is not only linear in the input features \(\mathbf{x}\), but also linear in the parameters \(\boldsymbol{\beta}\).
However, the more important focus is that the linearity is in the parameters \(\boldsymbol{\beta}\), not the input features \(\mathbf{x}\).
This will be made apparent in the section detailing on fitting non-linear inputs \(\mathbf{x}\). For example, consider a non-linear transformation map defined by \(\phi(\cdot)\), then \(\phi(\mathbf{x})\) is a non-linear function of \(\mathbf{x}\). But if we write the linear regression model as follows:
Then we can see that the linearity is in the parameters \(\boldsymbol{\beta}\), not the input features \(\mathbf{x}\). Therefore, this expression is still a valid form of “linear regression”.
Basis Function and Non-Linearity#
What immediately follows from the previous section on linearity in parameters is that we can model non-linear functions by using a non-linear transformation map \(\phi(\cdot)\).
Consider the basis function \(\boldsymbol{\phi(\cdot)}\) defined as follows:
Notice that \(\boldsymbol{\phi(\cdot)}\) is a bolded, and is a function that maps a vector \(\mathbf{x}\) of dimension \(D\) to a vector \(\boldsymbol{\phi}(\mathbf{x})\) of dimension \(K\).
We can decompose the basis function \(\boldsymbol{\phi(\cdot)}\) into a set of basis functions \(\phi_1(\cdot), \phi_2(\cdot), \ldots, \phi_K(\cdot)\) as follows:
for the \(k\)-th component of the feature vector \(\boldsymbol{\phi}\). Now we can write the linear regression model as follows:
Then if you denote \(\mathbf{z} = \boldsymbol{\phi}(\mathbf{x})\), then the form is still exactly the same as (143).
The takeaway is that we can model non-linear functions by using a non-linear transformation map \(\phi(\cdot)\). So we are not restricted to modelling lines and hyperplanes, but can model any function that can be expressed as a linear combination of basis functions.
We will not dive too deep into this topic, but related content can be found in the references section.
Matrix Representation#
Remark 38 (Notation Convention)
We have loosely used \(\mathbf{X}\) earlier to denote a random variable, from now on, we will use \(\mathbf{X}\) to denote the design matrix (explained below).
We can represent the linear regression model in matrix form by collecting all the input features \(\mathbf{x}\) into a matrix \(\mathbf{X}\), and all the target variables \(y\) into a vector \(\mathbf{y}\), as shown below:
or equivalently,
where
\(\mathbf{X}\) is the Design Matrix of shape \(N \times D\) where \(N\) is the number of observations (training samples) and \(D\) is the number of independent feature/input variables.
\[\begin{split} \mathbf{X} = \begin{bmatrix} 1 & x_1^{(1)} & x_2^{(1)} & \cdots & x_D^{(1)} \\ 1 & x_1^{(2)} & x_2^{(2)} & \cdots & x_D^{(2)} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ 1 & x_1^{(N)} & x_2^{(N)} & \cdots & x_D^{(N)} \end{bmatrix}_{N \times (D+1)} = \begin{bmatrix} \left(\mathbf{x^{(1)}}\right)^{T} \\ \left(\mathbf{x^{(2)}}\right)^{T} \\ \vdots \\ \left(\mathbf{x^{(N)}}\right)^{T}\end{bmatrix} \end{split}\]The \(n\)-th row of \(\mathbf{X}\) is defined as the transpose of \(\mathbf{x}^{(n)}\), which is also known as the \(n\)-th training sample, represented as a \(D+1\)-dimensional vector.
\[\begin{split} \mathbf{x}^{(n)} = \begin{bmatrix} 1 \\ x_1^{(n)} \\ x_2^{(n)} \\ \vdots \\ x_D^{(n)} \end{bmatrix}_{(D+1) \times 1} \end{split}\]where \(x_d^{(n)}\) is the \(d\)-th feature of the \(n\)-th training sample.
\(\mathbf{y}\) the output is a column vector that contains the output for the \(N\) observations.
\[\begin{split} \mathbf{y} = \begin{bmatrix} y^{(1)} \\ y^{(2)} \\ \vdots \\ y^{(N)} \end{bmatrix}_{N \times 1} \end{split}\]\(\boldsymbol{\beta}\) the vector of coefficients/parameters: The column vector \(\boldsymbol{\beta}\) contains all the coefficients of the linear model.
\[\begin{split}\boldsymbol{\beta} = \begin{bmatrix} \beta_0 \\ \beta_1 \\ \vdots \\ \beta_D \end{bmatrix}_{(D+1) \times 1}\end{split}\]\(\boldsymbol{\varepsilon}\) the random vector of the error terms: The column vector \(\boldsymbol{\varepsilon}\) contains \(N\) error terms corresponding to the \(N\) observations.
\[\begin{split} \boldsymbol{\varepsilon} = \begin{bmatrix} \varepsilon^{(1)} \\ \varepsilon^{(2)} \\ \vdots \\ \varepsilon^{(N)} \end{bmatrix}_{N \times 1} \end{split}\]
As we move along, we will make slight modification to the variables above, to accommodate the intercept term as seen in the Design Matrix.
Break down of the Matrix Representation#
A multivariate linear regression problem between an input variable \(\mathbf{x}^{(n)}\) and output variable \(y^{(n)}\) can be represented as such:
Since there exists \(N\) observations, we can write an equation for each observation:
where \(x_0^{(n)} = 1\) for all \(n\) is the intercept term.
We transform the above system of linear equations into matrix form as follows:
We then write the above system of linear equations more compactly as y = Xβ + \(\boldsymbol{\varepsilon}\) where \(ε\sim^{\text{i.i.d}}N(0, σ^2)\) recovering back the equation at the start.
In what follows, we will restate some definitions again, and use the matrix representation in (151) to derive the closed-form solution for the coefficients \(\boldsymbol{\beta}\).
Hypothesis Space#
Given the sample dataset \(\mathcal{S} = \left\{\mathbf{x}^{(n)}, y^{(n)}\right\}_{n=1}^N\), the hypothesis space \(\mathcal{H}\) is the set of all functions \(h: \mathbb{R}^D \rightarrow \mathbb{R}\) that can be learned from the dataset \(\mathcal{S}\).
We mentioned in the first section that the hypothesis space is given by:
Now, we have also defined in basis function and non-linearity that we can model non-linearity. Therefore, the hypothesis space can be expanded to include non-linear functions.
where \(\mathbf{\phi}(\mathbf{x})\) is a non-linear function that maps \(\mathbf{x}\) to a higher dimensional space \(\mathbb{R}^D\).
Loss Function#
As mentioned in the first section, we will be using the mean squared error (MSE) as our loss function.
We define a loss function \(\mathcal{L}\) that measures the error between the true label \(y\) and the predicted label \(\hat{h}\left(\mathbf{x}; \boldsymbol{\beta}\right)\).
We present a few equivalent notations for the loss function \(\mathcal{L}\):
where the last equation is to emphasize that the loss function \(\mathcal{L}\) is a function of the weight vector \(\boldsymbol{\beta}\) and not of the input \(\mathbf{x}\) for the context of machine learning.
The choice of loss function in regression is often the mean squared error loss (MSE) defined by:
where we used the fact that \(\hat{y} = \boldsymbol{\beta}^T \mathbf{x}\).
Then for our empirical loss, we can write:
to indicate that the empirical loss is a function of the hypothesis \(h\) and the dataset \(\mathcal{S}\).
We will detail in the next section on why the mean squared error loss is a sensible choice, amongst others.
Cost Function#
The cost function \(\mathcal{J}\) is the expected loss over the entire input-output space \(\mathcal{X} \times \mathcal{Y}\).
Of course, we are not able to compute the expected loss over the entire input-output space \(\mathcal{X} \times \mathcal{Y}\), so we look at the expected loss over the training dataset \(\mathcal{S}\), denoted by \(\widehat{\mathcal{J}}\). This is the cost function and is just the empirical risk function defined in (139).
where the last equation is due to our matrix representation, a more concise notation.
Note that we also expressed the cost function as \(\widehat{\mathcal{J}}\left(\boldsymbol{\beta} \mid \mathcal{S}\right)\) to emphasize that the cost function is a function of the weight vector \(\boldsymbol{\beta}\) and not of the input \(\mathbf{x}\). This is because in optimization, we are trying to find the weight vector \(\boldsymbol{\beta}\) that minimizes the cost function, so we will be taking the derivative of the cost function with respect to the weight vector \(\boldsymbol{\beta}\) later.
Convexity and Differentiability#
The cost function \(\widehat{\mathcal{J}}\left(\boldsymbol{\beta} \mid \mathcal{S}\right)\) is a convex function of the weight vector \(\boldsymbol{\beta}\).
This is relatively easy to see as the cost function is a quadratic function of the weight vector \(\boldsymbol{\beta}\) and hence the convexity of the cost function follows from the convexity of the quadratic function.
Moreover, it is also differentiable with respect to the weight vector \(\boldsymbol{\beta}\).
Why are these important? Well, maybe not that much in Linear Regression, since there exists a closed-form solution to the optimization problem.
But in gradient-based optimization, we will need to take the derivative of the cost function with respect to the weight vector \(\boldsymbol{\beta}\). Consequently, convexity guarantees that the optimization problem has a global optima and differentiability guarantees that we can find the optimal weight vector \(\hat{\boldsymbol{\beta}}\) by taking the derivative of the cost function with respect to the weight vector \(\boldsymbol{\beta}\).
Objective Function#
We now formulate the optimization problem in terms of the objective function.
where \(\boldsymbol{\Theta}\) is the set of all possible weight vectors \(\boldsymbol{\beta}\).
Equivalently, we are finding the below:
where \(\hat{\boldsymbol{\beta}}\) is the optimal estimate of the weight vector \(\boldsymbol{\beta}\).
Model Fitting via Least Squares#
This method need no assumptions on the distribution of the data and just involves minimizing the objective function (159) with respect to the weight vector \(\boldsymbol{\beta}\). In other words, we are finding the weight vector \(\boldsymbol{\beta}\) that minimizes the mean squared error (MSE) between the predicted values \(\mathbf{\hat{y}}\) and the actual values \(\mathbf{y}\).
Solving for 1-Dimensional Case#
Let’s consider the base case where each sample is a scalar, i.e. \(\mathbf{x}^{(n)} \in \mathbb{R}\). That is to say, we seek to find:
where the last equality expands the matrix-vector product \(\mathbf{X} \boldsymbol{\beta}\) into its constituent elements. This is a step back from the matrix representation of the data, but it is useful for understanding the optimization problem and how to take derivatives at 2-Dimensional.
The following proof adapts from [Chan, 2021].
Proof. As with any two-dimensional optimization problem, the optimal point \((\hat{\beta}_1, \hat{\beta}_0)\) should have a zero gradient, meaning that
This should be familiar to you, even if you have only learned basic calculus. This pair of equations says that, at \(\hat{\beta}_1\) minimum point, the directional slopes should be zero no matter which direction you are looking at. The derivative with respect to \(\hat{\beta}_1\) is
Similarly, the derivative with respect to \(\hat{\beta}_0\) is
Setting these two equations to zero, we have that
where
\(\bar{y} = \frac{1}{N} \sum_{n=1}^N y^{(n)}\) is the sample mean of the response variable \(Y\);
\(\bar{x} = \frac{1}{N} \sum_{n=1}^N x^{(n)}\) is the sample mean of the predictor variable \(X\).
\(s_Y = \sqrt{\frac{1}{N-1} \sum_{n=1}^N \left(y^{(n)} - \bar{y}\right)^2}\) is the sample standard deviation of the response variable \(Y\);
\(s_X = \sqrt{\frac{1}{N-1} \sum_{n=1}^N \left(x^{(n)} - \bar{x}\right)^2}\) is the sample standard deviation of the predictor variable \(X\);
\(r_{XY} = \frac{\sum_{n=1}^N \left(x^{(n)} - \bar{x}\right) \left(y^{(n)} - \bar{y}\right)}{\sqrt{\sum_{n=1}^N \left(x^{(n)} - \bar{x}\right)^2} \sqrt{\sum_{n=1}^N \left(y^{(n)} - \bar{y}\right)^2}}\) is the sample correlation coefficient between the response and predictor variables.
Thus, we conclude that the optimal estimates of \(\beta_0\) and \(\beta_1\) are given by:
We can also see that the second derivative of both the equations gives us more than \(0\), indicating that the solution found is a global minimum (convexity).
Solving for \(D\)-Dimensional Case#
We can generalize the above to the \(D\)-dimensional case. We have in equation (150) that we can write the linear regression formulation more compactly as
We will minimize (159) with respect to \(\boldsymbol{\beta}\).
With some matrix calculus, we can derive that:
Equating it to \(\boldsymbol{0}\), we get:
and we call this the normal equations. We can solve for \(\hat{\boldsymbol{\beta}}\) to get the estimates of \(\boldsymbol{\beta}\).
To solve for \(\hat{\boldsymbol{\beta}}\), we can use the matrix inverse of \(\mathbf{X}^T \mathbf{X}\) to get:
Model Fitting via Maximum Likelihood Estimation#
We now have the objective function, so we can use it to find the optimal weight vector \(\hat{\boldsymbol{\beta}}\). We could directly set the derivative of the cost function in (158) to \(0\) and solve for \(\hat{\boldsymbol{\beta}}\). This is solvable and has a closed-form solution. However, we will take the probabilistic approach where we will be invoking maximum likelihood estimation (MLE) to find the optimal weight vector \(\hat{\boldsymbol{\beta}}\). We will show that the maximizing the log-likelihood is equivalent to minimizing the cost function.
We split into two steps, finding the likelihood function and then finding the maximum likelihood estimate (MLE) separately.
With slight abuse of notation, we denote the following:
where \(\mathbf{x}^{(n)} \in \mathbb{R}^{D}\) is the \(n\)-th input and \(y^{(n)} \in \mathbb{R}\) is the \(n\)-th output.
IID Assumption#
When applying MLE, it is often assumed that the data is independent and identically distributed (IID). However, in the case of linear regression, we are finding the conditional likelihood function and thus the identical distribution assumption is not fulfilled, and is also not required.
More concretely, we have the following (adapted from here):
\(y \mid \mathbf{x} \sim \mathcal{N}(\boldsymbol{\beta}^T \mathbf{x}, \sigma^2)\) and here we see that for a different \(\mathbf{x}\), the distribution of \(y\) is different. Hence the identically distributed assumption is not fulfilled.
However, \(Y^{(n)} \mid X^{(n)} = \mathbf{x}^{(n)}\) is however identically distributed because now the \(\mathbf{x}^{(n)}\) is fixed and we are only varying \(y^{(n)}\).
The response variables are conditionally independent conditional on the explanatory variable. As a shorthand we may say that the values \(y^{(n)} \mid \mathbf{x}^{(n)}\) are independent (though not identically distributed).
This is a much stronger assumption than in regression analysis. It is equivalent to making the standard regression assumptions, but also assuming that the underlying explanatory variables are IID. Once you assume that \(X^{(1)}, X^{(2)}, \ldots, X^{(N)}\) are IID , the regression assumptions imply that the response variable is also marginally IID, which gives the joint IID result. So there is nothing wrong in our problem formulation to say that the joint tuple \(\{\mathbf{x}^{(n)}, y^{(n)}\}_{n=1}^{N}\) is IID.
Conditional Likelihood Function#
Definition 55 (Conditional Likelihood Function)
The conditional likelihood function is the probability of observing the dataset \(\mathcal{S}\) given the model parameters \(\boldsymbol{\beta}\).
where
\((*)\) is due to the fact that we are assuming that the conditional distribution of the output given the input is a normal distribution with mean \(\boldsymbol{\beta}^{\top} \mathbf{x}^{(n)}\) and variance \(\sigma^2\), as detailed earlier, a consequence of the noise term \(\varphi\) being normally distributed;
\((**)\) is vectorizing the summation.
Remark 39 (Notation Clash)
There is a notation clash here since \(\mathcal{L}\) is overloaded with the likelihood function and the loss function. We will continue using it as it is when the context is clear. Moreover, we will soon realize that both the likelihood function and the loss function are related in a way that minimizing the loss function is equivalent to maximizing the likelihood function. There is however still notation abuse since the likelihood function is more similar to the cost function as it takes all the data points into account.
For more details, see Definition 171 in the section on conditional likelihood.
Conditional Log-Likelihood Function#
It is typical to work with the log-likelihood function instead of the likelihood function since it can cause numerical underflow when the likelihood function is very small. That means computers cannot multiply very small numbers together. Imagine multiplying \(1\) billion of \(10^{-100}\) together, the result is \(0\) in floating point arithmetic. But adding the log of \(10^{-100}\) billion times is no longer causing numerical underflow.
Furthermore, all we need to know is that we are maximizing the likelihood function, and since log is a monotonic function, maximizing the log-likelihood function is equivalent to maximizing the likelihood function, meaning they return the same optimal parameters.
Definition 56 (Conditional Log-Likelihood Function)
The conditional log-likelihood function is the log of the probability of observing the dataset \(\mathcal{S}\) given the model parameters \(\boldsymbol{\beta}\) is defined as the log of the conditional likelihood function in Definition 55.
We should already see where this is going. The right hand side of equation (166) has a term \(\left\|\mathbf{y} - \mathbf{X} \boldsymbol{\beta}\right\|_2^2\) which looks very similar to the loss function in (158).
Maximum Likelihood Estimation#
With the likelihood function defined, we can start our discussion on Maximum Likelihood Estimation (MLE).
Since likelihood function, we can maximize it to find the optimal parameters \(\hat{\boldsymbol{\beta}}\).
Recall in the objective function in (160) below, we are minimizing the cost function.
To do the same, instead of maximizing the log-likelihood function, we can minimize the negative log-likelihood function, which yields the same optimal parameters.
We seek to find the optimal parameters \(\hat{\boldsymbol{\beta}}\) that minimize the negative log-likelihood function. We compute the gradient of the negative log-likelihood function with respect to the parameters \(\boldsymbol{\beta}\):
where
\((*)\) is the expansion of the norm \(\left\|\mathbf{y} - \mathbf{X} \hat{\boldsymbol{\beta}}\right\|_2^2\).
\((**)\) is the chain rule, where \(\frac{\partial}{\partial \boldsymbol{\beta}} \boldsymbol{\beta}^T \mathbf{A} \boldsymbol{\beta} = \mathbf{A} + \mathbf{A}^T\).
Next, we will set the gradient to zero and solve for the optimal parameters \(\hat{\boldsymbol{\beta}}\).
where
\((\star)\) is just rearranging the terms.
\((\star \star)\) is the definition of the matrix inverse where we right-multiply the by \(\left(\mathbf{X}^T \mathbf{X}\right)^{-1}\). This is allowed because \(\left(\mathbf{X}^T \mathbf{X}\right)\) is positive definite (invertible) and rank of \(\mathbf{X}\) is \(D\).
We now see that the solution is the same as the solution to the normal equations.
MLE estimates the conditional expectation of the target variable given the input#
In (146), we saw that linear regression can be expressed as a conditional expectation of the target variable given the input under the probabilistic model.
Therefore, the MLE estimate \(\hat{\boldsymbol{\beta}}\), when plugged into the equation
gives us the estimate of the conditional expectation of the target variable given the input.
See here for more info.
Performance Metrics#
While not the focus of this post, we will briefly discuss some of the most common performance metrics for linear regression.
Mean Squared Error (MSE)#
As we have seen earlier in the loss function section, the Mean Squared Error (MSE) can also be used to evaluate the performance of a linear regression model.
Mean Squared Error (MSE) is a widely used metric for evaluating the performance of regression models. It represents the average of the squared differences between the actual values and the predicted values of the dependent variable. Lower MSE values indicate a better fit of the model, as the squared differences between the predicted and actual values are smaller on average.
The MSE is calculated as follows:
where:
\(\text{MSE}\) is the Mean Squared Error,
\(N\) is the number of observations,
\(y^{(n)}\) is the actual value of the dependent variable for observation \(n\),
\(\hat{y}^{(n)}\) is the predicted value of the dependent variable for observation \(n\).
MSE has several desirable properties as a loss function for regression tasks:
It is non-negative, meaning that it always returns a positive value, or zero when the predictions are perfect.
It penalizes larger errors more heavily than smaller errors, as the differences between the predicted and actual values are squared. This makes the model more sensitive to outliers and encourages it to fit the data more closely.
It is differentiable, which allows for the application of optimization techniques like gradient descent to find the best model parameters.
However, MSE has some limitations:
The squared differences can lead to overemphasis on outliers, which might not be desirable in some applications.
The scale of MSE depends on the scale of the dependent variable, making it challenging to compare the performance of models with different output scales.
In practice, other metrics like Root Mean Squared Error (RMSE) or Mean Absolute Error (MAE) can be used alongside MSE to better understand the model’s performance and address its limitations.
R-Squared#
R-squared (\(R^2\)) is a statistical measure that represents the proportion of the variance in the dependent variable (response) that can be explained by the independent variables (predictors) in a linear regression model. It is a value between 0 and 1, and a higher R-squared value indicates a better fit of the model. The R-squared metric can be understood as the proportion of variation in the data that is accounted for by the fitted model.
Definition 57 (R-squared)
The R-squared value is defined as:
where:
\(R^2\) is the R-squared value,
\(SS_{res}\) is the residual sum of squares (sum of the squared differences between the actual and predicted values),
\(SS_{tot}\) is the total sum of squares (sum of the squared differences between the actual values and the mean of the actual values).
Mathematically, the residual sum of squares is defined as:
And the total sum of squares is defined as:
where:
\(N\) is the number of observations,
\(y^{(n)}\) is the actual value of the dependent variable for observation \(n\),
\(\hat{y}^{(n)}\) is the predicted value of the dependent variable for observation \(n\),
\(\bar{y}\) is the mean of the actual values of the dependent variable.
One should realize that \(SS_{tot}\) refers to the total variation in the response variable, which can be thought of as the amount of variation inherently in the response before we fit the regression model. In constrast, \(SS_{res}\) refers to the variation in the response variable that is left unexplained after fitting the regression model.
Consequently, the definition of R-squared is fairly straight-forward; it is the percentage of the response variable variation that is explained by a linear model. In other words, R-squared is Explained variation / Total variation.
R-squared is always between 0 and 100% where
0% indicates that the model explains none of the variability of the response data around its mean.
100% indicates that the model explains all the variability of the response data around its mean.
As popular as it is, R-squared is not without its flaws.
Every time you add a predictor to a model, the R-squared increases, even if due to chance alone. It never decreases. Consequently, a model with more terms may appear to have a better fit simply because it has more terms.
If a model has too many predictors and higher order polynomials, it begins to model the random noise in the data. This condition is known as overfitting the model and it produces misleadingly high R-squared values and a lessened ability to make predictions.
A limitation of R-squared is that it can only increase, or stay the same, as you add more predictors to the model, even if those predictors are not truly improving the model’s fit. This is why it’s important to consider other metrics like adjusted R-squared, which penalizes the model for the inclusion of unnecessary predictors, or use other methods like cross-validation to evaluate the model’s performance.
Adjusted R-Squared#
To address the limitations of R-squared, we can use the adjusted R-squared metric, where it is a modification of the R-squared (\(R^2\)) metric that takes into account the number of predictors in a linear regression model. It adjusts the R-squared value to account for the addition of predictors, preventing the artificial inflation of the R-squared value when adding more predictors that may not necessarily improve the model’s fit.
See here for more information.
Assumptions of Linear Regression#
This section is adapted from the blog post, Linear Regression Assumptions by Jeff Macaluso.
While it is important for one to check the assumptions of linear regression, it is also important to know that we do not require them to fit the model. We only require them to interpret the model. The difference is subtle, but important. If you view the linear regression from the Ordinary Least Squares (OLS) perspective, then the only assumption you need is for the matrix \(\mathbf{X}^T\mathbf{X}\) to be invertible.
For a more rigorous treatment of the assumptions of linear regression, see here.
Linearity#
This assumes that there is a linear relationship between the predictors (e.g. independent variables or features) and the response variable (e.g. dependent variable or label). This also assumes that the predictors are additive.
Why it can happen: There may not just be a linear relationship among the data. Modeling is about trying to estimate a function that explains a process, and linear regression would not be a fitting estimator (pun intended) if there is no linear relationship.
What it will affect: The predictions will be extremely inaccurate because our model is underfitting. This is a serious violation that should not be ignored. However, do not forget we have learnt that we can model non-linear relationships using polynomial regression.
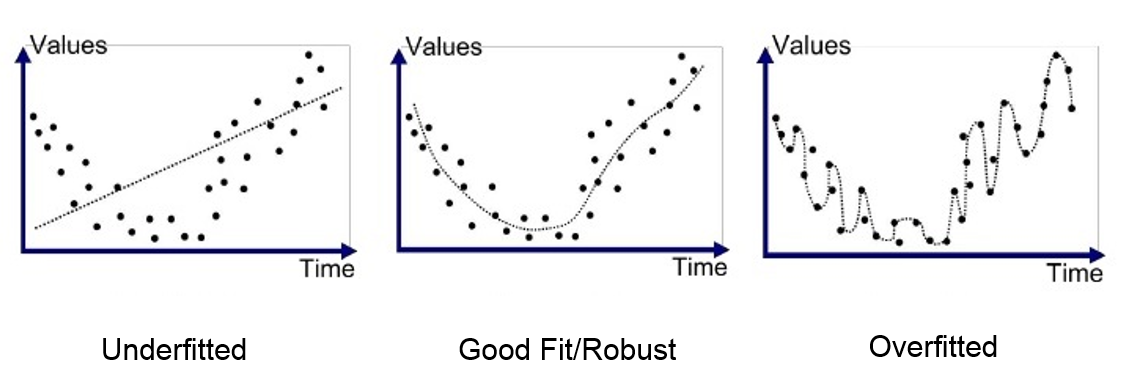{kind=link}
How to detect it: If there is only one predictor, this is pretty easy to test with a scatter plot. Most cases aren’t so simple, so we’ll have to modify this by using a scatter plot to see our predicted values versus the actual values (in other words, view the residuals). Ideally, the points should lie on or around a diagonal line on the scatter plot.
How to fix it: Either adding polynomial terms to some of the predictors or applying nonlinear transformations . If those do not work, try adding additional variables to help capture the relationship between the predictors and the label.
We can see that the data is linearly related to the fitted values. This is a good sign that the linear regression model is appropriate for this dataset.
Show code cell source
1# Load your dataset
2# df = pd.read_csv('your_dataset.csv')
3
4# For illustration purposes, we create a sample dataset
5np.random.seed(42)
6X = np.random.rand(100)
7y = 2 * X + 1 + 0.1 * np.random.randn(100)
8df = pd.DataFrame({'X': X, 'y': y})
9
10# Fit the linear regression model
11X = sm.add_constant(df['X'])
12model = sm.OLS(df['y'], X).fit()
13
14# Assumption 1: Linearity
15# Use a scatter plot and the fitted values to visually inspect linearity
16plt.scatter(df['X'], df['y'], label='Data')
17plt.plot(df['X'], model.fittedvalues, color='red', label='Fitted Line')
18plt.legend()
19plt.xlabel('X')
20plt.ylabel('y')
21plt.title('Linearity Check')
22plt.show();

Homoscedasticity#
This assumes homoscedasticity, which is the same variance within our error terms. Heteroscedasticity, the violation of homoscedasticity, occurs when we don’t have an even variance across the error terms.
Why it can happen: Our model may be giving too much weight to a subset of the data, particularly where the error variance was the largest.
What it will affect: Significance tests for coefficients due to the standard errors being biased. Additionally, the confidence intervals will be either too wide or too narrow.
How to detect it: Plot the residuals and see if the variance appears to be uniform.
How to fix it: Heteroscedasticity (can you tell I like the scedasticity words?) can be solved either by using weighted least squares regression instead of the standard OLS or transforming either the dependent or highly skewed variables. Performing a log transformation on the dependent variable is not a bad place to start.
Show code cell source
1# Assumption 2: Homoscedasticity
2# Use a scatter plot of residuals vs. fitted values to visually inspect homoscedasticity
3residuals = model.resid
4plt.scatter(model.fittedvalues, residuals)
5plt.axhline(y=0, color='r', linestyle='--')
6plt.xlabel('Fitted Values')
7plt.ylabel('Residuals')
8plt.title('Homoscedasticity Check')
9plt.show();

Normality of the Error Terms#
More specifically, this assumes that the error terms of the model are normally distributed. Linear regressions other than Ordinary Least Squares (OLS) may also assume normality of the predictors or the label, but that is not the case here.
Why it can happen: This can actually happen if either the predictors or the label are significantly non-normal. Other potential reasons could include the linearity assumption being violated or outliers affecting our model.
What it will affect: A violation of this assumption could cause issues with either shrinking or inflating our confidence intervals.
How to detect it: There are a variety of ways to do so, but we’ll look at both a histogram and the p-value from the Anderson-Darling test for normality.
How to fix it: It depends on the root cause, but there are a few options. Nonlinear transformations of the variables, excluding specific variables (such as long-tailed variables), or removing outliers may solve this problem.
Show code cell source
1# Assumption 3: Normality of error terms
2# Use a Q-Q plot to visually inspect normality
3sm.qqplot(residuals, line='45', fit=True)
4plt.title('Normality Check - Q-Q Plot')
5plt.show();
6
7# Alternatively, use the Shapiro-Wilk test for normality
8# (Null hypothesis: The residuals are normally distributed)
9shapiro_test = stats.shapiro(residuals)
10print('Shapiro-Wilk Test:', shapiro_test)

Shapiro-Wilk Test: ShapiroResult(statistic=0.9846267871943117, pvalue=0.29841614058046384)
No Autocorrelation between Error Terms#
This assumes no autocorrelation of the error terms. Autocorrelation being present typically indicates that we are missing some information that should be captured by the model.
Why it can happen: In a time series scenario, there could be information about the past that we aren’t capturing. In a non-time series scenario, our model could be systematically biased by either under or over predicting in certain conditions. Lastly, this could be a result of a violation of the linearity assumption.
What it will affect: This will impact our model estimates.
How to detect it: We will perform a Durbin-Watson test to determine if either positive or negative correlation is present. Alternatively, you could create plots of residual autocorrelations.
How to fix it: A simple fix of adding lag variables can fix this problem. Alternatively, interaction terms, additional variables, or additional transformations may fix this.
We can use the some tests such as Durbin-Watson test to check for autocorrelation. The null hypothesis of the Durbin-Watson test is that there is no autocorrelation. The test statistic is a number between 0 and 4. The closer the test statistic is to 0, the more positive autocorrelation there is. The closer the test statistic is to 4, the more negative autocorrelation there is. A value of 2 indicates no autocorrelation.
Show code cell source
1# Assumption: No autocorrelation in residuals
2# Use the Durbin-Watson test to check for autocorrelation
3# (Null hypothesis: No autocorrelation in the residuals)
4durbin_watson_stat = durbin_watson(model.resid)
5print('Durbin-Watson statistic:', durbin_watson_stat)
6
7# A value close to 2 indicates no autocorrelation,
8# while values < 2 or > 2 indicate positive or negative autocorrelation, respectively.
9
10# Alternatively, you can use a plot of residuals vs. time
11residuals = model.resid
12plt.plot(residuals)
13plt.axhline(y=0, color='r', linestyle='--')
14plt.xlabel('Time')
15plt.ylabel('Residuals')
16plt.title('Autocorrelation Check - Residuals vs. Time')
17plt.show()
18
19# You can also use the ACF (Autocorrelation Function) plot from the statsmodels library
20from statsmodels.graphics.tsaplots import plot_acf
21
22plot_acf(residuals, lags=20, title='Autocorrelation Check - ACF plot')
23plt.show();
Durbin-Watson statistic: 2.2849976037296673


Multicollinearity among Predictors#
This assumes that the predictors used in the regression are not correlated with each other. This won’t render our model unusable if violated, but it will cause issues with the interpretability of the model. This is why in the previous section, we need to make sure that the 3 variables, square feet, number of bedrooms, age of house are not highly correlated with each other, else additive effects may happen.
Why it can happen: A lot of data is just naturally correlated. For example, if trying to predict a house price with square footage, the number of bedrooms, and the number of bathrooms, we can expect to see correlation between those three variables because bedrooms and bathrooms make up a portion of square footage.
What it will affect: Multicollinearity causes issues with the interpretation of the coefficients. Specifically, you can interpret a coefficient as “an increase of 1 in this predictor results in a change of (coefficient) in the response variable, holding all other predictors constant.” This becomes problematic when multicollinearity is present because we can’t hold correlated predictors constant. Additionally, it increases the standard error of the coefficients, which results in them potentially showing as statistically insignificant when they might actually be significant.
How to detect it: There are a few ways, but we will use a heatmap of the correlation as a visual aid and examine the variance inflation factor (VIF).
How to fix it: This can be fixed by other removing predictors with a high variance inflation factor (VIF) or performing dimensionality reduction.
Let’s create another dataset to see how to detect multicollinearity.
Show code cell source
1# Assumption 5: No perfect multicollinearity
2# For a simple linear regression, multicollinearity is not an issue.
3# For multiple linear regression, check the variance inflation factor (VIF)
4from statsmodels.stats.outliers_influence import variance_inflation_factor
5
6# Load your multiple linear regression dataset
7# df_multi = pd.read_csv('your_multi_dataset.csv')
8
9# For illustration purposes, we create a sample dataset with three variables
10np.random.seed(42)
11X1 = np.random.rand(100)
12X2 = X1 + 0.1 * np.random.randn(100)
13X3 = 0.5 * X1 + 0.5 * X2 + 0.1 * np.random.randn(100)
14y_multi = 2 * X1 + 3 * X2 - 1 * X3 + 1 + 0.1 * np.random.randn(100)
15df_multi = pd.DataFrame({'X1': X1, 'X2': X2, 'X3': X3, 'y': y_multi})
16
17# Fit the multiple linear regression model
18X_multi = sm.add_constant(df_multi[['X1', 'X2', 'X3']])
19model_multi = sm.OLS(df_multi['y'], X_multi).fit()
20
21# Assumption: No perfect multicollinearity
22# Check the variance inflation factor (VIF) for each independent variable
23vif = pd.DataFrame()
24vif['Features'] = ['X1', 'X2', 'X3']
25vif['VIF'] = [variance_inflation_factor(X_multi.values, i + 1) for i in range(len(vif['Features']))]
26print('VIF:')
27display(vif)
28
29# Use a heatmap to visualize the correlation between variables
30corr_matrix = df_multi[['X1', 'X2', 'X3']].corr()
31plt.figure(figsize=(8, 6))
32sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', cbar=True, square=True, fmt='.2f', linewidths=.5)
33plt.title('Heatmap Correlation Plot')
34plt.show();
VIF:
| Features | VIF | |
|---|---|---|
| 0 | X1 | 12.928109 |
| 1 | X2 | 12.534023 |
| 2 | X3 | 8.184352 |

Feature Scaling#
Do we need to scale the features before fitting a linear regression model?
This question is often asked in the context of multiple linear regression, but it is actually a more general question about the use of standardization and normalization in machine learning.
The scale and location of the explanatory variables does not affect the validity of the regression model in any way.
Consider the model \(y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_3 + \varepsilon\). If you scale \(x_1\) by a factor \(a\), the model becomes \(y = \beta_0 + \beta_1 a x_1 + \beta_2 x_2 + \beta_3 x_3 + \epsilon\). The coefficients \(\beta_1, \beta_2, \beta_3\) are not affected by this scaling. The reason is that these are the slopes of the fitting surface - how much the surface changes if you change \(x_1, x_2, x_3\) one unit. This does not depend on location. (The intercept \(\beta_0\) does depend on location, but this is not a problem.)
Let’s see for ourselves.
Let’s look at the feature \(x_1\) and its corresponding coefficient \(\hat{\beta}_1\).
We claim that scaling \(x_1\) with a factor \(a\) scales \(\hat{\beta}_1\)by a factor \(\frac{1}{a}\). To see this, note that
Thus
Thus, scaling simply corresponds to scaling the corresponding slopes. Because if we scale square feet (\(x_1\)) by a factor of \(\frac{1}{10}\), then if the original \(\hat{\beta}_1\) was square feet is 100, then the above shows that the new \(\hat{\beta}_1\) will be multiplied by 10, becoming 1000, therefore, the interpretation of the coefficients did not change.
However, if you are using Gradient Descent (an optimization algorithm) in Regression, then centering, or scaling the variables, may prove to be faster for convergence.
Model Inference#
Say we have obtained the following estimates for the coefficients of the multiple linear regression model:
and so our estimated model \(\hat{y}: = \hat{h}(\mathbf{x})\) of the ground truth \(y:= f(\mathbf{x})\) is:
where
\(x_1 = \text{square feet}\),
\(x_2 = \text{number of bed rooms}\),
\(x_3 = \text{age of house}\)
The coefficient value signifies how much the mean of the dependent variable \(y\) changes given a one-unit shift in the independent variable \(x\) while holding other variables in the model constant. This property of holding the other variables constant is crucial because it allows you to assess the effect of each variable in isolation from the others.
For example, if we hold the number of bedrooms and age of house constant, then the coefficient of square feet is 139, which means that for every additional square foot, the price of the house increases by 139 dollars.
Mean Squared Error is an Unbiased Estimator of the Variance of the Error#
Mean Squared Error (MSE) is a commonly used metric for evaluating the performance of a regression model. It measures the average squared difference between the predicted values and the actual values. In the context of linear regression, the MSE is an unbiased estimator of the variance of the error term. This means that, on average, the MSE is equal to the true variance of the error term in the population.
The MSE is defined as:
Where:
\(N\) is the number of observations.
\(y^{(n)}\) is the actual value of the dependent variable for observation \(n\).
\(\hat{y}^{(n)}\) is the predicted value of the dependent variable for observation \(n\).
In the context of linear regression, the error term is defined as the difference between the actual value and the predicted value:
The variance of the error term is:
However, in practice, we do not know the true values of the parameters \(\beta_0, \beta_1, \ldots, \beta_D\). We estimate them using the sample data \(\mathcal{S}\), which gives us the predicted values \(\hat{y}^{(n)} = \beta_0 + \beta_1 x_1^{(n)} + \ldots \beta_D x_D^{(n)}\). Therefore, the estimated variance of the error term is:
The MSE is an unbiased estimator of the variance of the error term because the expected value of the MSE is equal to the true variance of the error term:
This property is important because it ensures that the MSE provides an accurate measure of the model’s performance. If the MSE were a biased estimator, it would consistently overestimate or underestimate the true variance of the error term, leading to incorrect inferences about the model’s performance. Since the MSE is an unbiased estimator, it provides a reliable estimate of the model’s error variance, making it a useful metric for model evaluation and comparison.
Estimated Coefficients are Multivariate Normally Distributed#
With the assumption that the error term \(\varepsilon \mid X \sim N[0, \sigma^2\mathbf{I}]\), we derive the weaker condition[2] of \(\varepsilon \sim N[0, \sigma^2\mathbf{I}]\). It is necessary to make this assumption for us to know the distribution of \(\hat{\boldsymbol{\beta}}\), because without this assumption, we will be at a loss of what distribution \(\hat{\boldsymbol{\beta}}\) can take on. We claim first that since \(\boldsymbol{\varepsilon}|\mathbf{X} \sim N[0, \sigma^2\mathbf{I}]\) follows a multivariate normal distribution of mean \(0\) and variance \(\sigma^2\mathbf{I}\), then it implies that \(\hat{\boldsymbol{\beta}}\) also follows a multivariate normal distribution of mean \(\boldsymbol{\beta}\) and variance \(\sigma^2(\mathbf{X}^T\mathbf{X})^{-1}\).
To justify this, we need to recall the variance-covariance matrix for \(\hat{\boldsymbol{\beta}}\) to have variance \(\sigma^2(\mathbf{X}^T\mathbf{X})^{-1}\)\footnote{it is necessary to know the mean and variance of \(\boldsymbol{\varepsilon}\) in order to find the variance-covariance of \(\hat{\boldsymbol{\beta}}\).}, and earlier on we also established the proof of \(\hat{\boldsymbol{\beta}}\) being an unbiased estimator, which simply states that \(\mathrm{E}[\hat{\boldsymbol{\beta}}] = \boldsymbol{\beta}\). So we know the mean and variance of our OLS estimators \(\hat{\boldsymbol{\beta}}\), but one last question, why does \(\boldsymbol{\varepsilon}\) taking on a multivariate normal distribution imply that \(\hat{\boldsymbol{\beta}}\) must also follow a multivariate normal distribution?
This is a consequence of that \(\hat{\boldsymbol{\beta}}\) is a linear estimator, recall that we are treating \(\boldsymbol{\beta}\) and \(\mathbf{X}\) as constant and non-stochastic, and consequently \(\hat{\boldsymbol{\beta}}\) is linear function of the error vector \(\boldsymbol{\varepsilon}\).
And using the property that a linear transform of a normal random variable is normal, we can easily see that \(\hat{\boldsymbol{\beta}}\) must be normal as well since \(\hat{\boldsymbol{\beta}}\) is a linear transformation of \(\boldsymbol{\varepsilon}\).
Thus so far we established the least squares parameters \(\hat{\boldsymbol{\beta}}\) is normally distributed with mean \(\boldsymbol{\beta}\) and variance \(\sigma^2(\mathbf{X}^T\mathbf{X})^{-1}\). More formally, we say that \(\hat{\boldsymbol{\beta}}\) follows a multi-variate normal distribution because \(\hat{\boldsymbol{\beta}}\) is a random vector, the distinction is that the variance of \(\hat{\boldsymbol{\beta}}\) is now a variance-covariance matrix instead of just a variance vector. But recall we do not know the real value of \(\sigma^2\) and therefore we replace \(\sigma^2\) with the unbiased variance estimator of the error variance, which we define and name it to be the Mean Squared Error (MSE) It is useful to remind yourself that we are learning ML, although MSE has a slightly different formula from the MSE in sklearn, the end goal is the same, refer to Confusion on MSE.
Assessing the Accuracy of the Coefficient Estimates#
This section is adapted from An Introduction to Statistical Learning [James et al., 2022].
Recall that we are ultimately always interested in drawing conclusions about the population, not the particular sample we observed. This is an important sentence to understand, the reason we are testing our hypothesis on the population parameter instead of the estimated parameter is because we are interested in knowing our real population parameter, and we are using the estimated parameter to provide some statistical gauge. In the Simple Linear Regression setting, we are often interested in learning about the population intercept \(\beta_0\) and the population slope \(\beta_1\). As you know, confidence intervals and hypothesis tests are two related, but different, ways of learning about the values of population parameters. Here, we will learn how to calculate confidence intervals and conduct different hypothesis tests for both \(\beta_0\) and \(\beta_1\).We turn our heads back to the SLR section, because when we ingest and digest concepts, it is important to start from baby steps first and generalize.
As a continuation of our running example in the univariate setting, we have 1 predictor which is the area of the house, in square feet, and we are interested in learning about the population intercept \(\beta_0\) and the population slope \(\beta_1\).
As an example, assumed we have already learned that the estimated intercept \(\hat{\beta}_0\) and the estimated slope \(\hat{\beta}_1\) are given by:
where we round the numbers to the nearest integer for simplicity.
Show code cell source
1X = data['House Size (sqft)']
2y = data['Price ($)']
3coefficients = np.polyfit(X, y, 1)
4slope, intercept = coefficients[0], coefficients[1]
5print(f'Estimated intercept: {intercept:.2f}')
6print(f'Estimated slope: {slope:.2f}')
7
8plt.scatter(X, y)
9plt.plot(np.unique(X), np.poly1d(coefficients)(np.unique(X)), color='red')
10plt.xlabel('House Size (sqft)')
11plt.ylabel('Price ($)')
12plt.show()
Estimated intercept: 114418.53
Estimated slope: 961.70

As we can see above from both the fitted plot and the OLS coefficients, there does seem to be a linear relationship between the two. Furthermore, the OLS regression line’s equation can be easily calculated and given by:
where \(x_1\) is the area of the house in square feet.
And so we know the estimated slope parameter \(\hat{\beta_1}\) is \(962\), and apparently there exhibits a “relationship” between \(x_1\) and \(y\). Remember, if there is no relationship, then our optimal estimated parameter \(\hat{\beta}_1\) should be 0, as a coefficient of \(0\) means that \(x_1\) and \(y\) has no relationship (or at least in the linear form, the same however, cannot be said for non-linear models!). But be careful, although we can be certain that there is a relationship between house area and the sale price, but it is only limited to the \(100\) training samples that we have!
In fact, we want to know if there is a relationship between the population parameter of all of the house area and its corresponding sale price in the whole population (country). More concretely, we want to know if the true population slope is close to the estimated slope parameter \(\hat{\beta}_1\) that we have obtained from our sample.
It follows that we also want to ascertain that the true population slope \(\beta_1\)is unlikely to be 0 as well. Note that \(0\) is a common benchmark we use in linear regression, but it, in fact can be any number. This is why we have to draw inferences from \(\hat{\beta}_1\) to make substantiate conclusion on the true population slope \(\beta_1\).
Let us formulate our question/hypothesis by asking the question: Do our house area and sale price exhibit a true linear relationship in our population? Can we make inferences of our true population parameters based on the estimated parameters (OLS estimates)?
Thus, we can use the infamous scientific method Hypothesis Testing by defining our null hypothesis and alternate hypothesis as follows:
Null Hypothesis \(H_0\): \(\beta_1=0\)
Alternative Hypothesis \(H_1\): \(\beta_1\neq 0\)
Basically, the null hypothesis says that \(\beta_1=0\), indicating that there is no relationship between \(X\) and \(y\). Indeed, if \(\beta_1=0\), our original model reduces to \(y=\beta_0+\varepsilon\), and this shows \(X\) does not depend on \(y\) at all. To test the null hypothesis, we instead need to determine whether \(\hat{\beta}_1\), our OLS estimate for \(\beta_1\), is sufficiently far from 0 so that we are confident that the real parameter \(\beta_1\) is non-zero. Note the distinction here that we emphasized that we are performing a hypothesis testing on the true population parameter but we depend on the value of the estimate of the true population parameter since we have no way to know the underlying true population parameter.
Standard Error#
Now here is the intuition, yet again, we need to gain an understanding first before we go into further mathematical details. We already established subtly that even if we can easily calculate \(\hat\beta_1\), and it turns out to be non-zero, how can we feel “safe” that our true parameter \(\beta_1\) is also non-zero? Well if you think deeper, it all boils down to whether our \(\hat{\beta_1}\) is a good estimate of \(\beta_1\); and this can be quantified by checking the standard error of \(\hat{\beta_1}\). By definition, we should remember the standard error of \(\hat{\beta_1}\) means the amount of dispersion of the various \(\hat\beta_1\) around its mean (recall the mean of \(\hat\beta_1\) is \(\beta_1\)). So if \(\text{SE}(\hat{\beta_1})\) is small, this means \(\hat{\beta_1}\) does not vary much around its mean and recall that the mean of \(\hat{\beta_1}\) is none other than \(\beta_1\) due to the unbiasedness property of OLS estimator; consequently, it is quite “safe” to say that which ever sample you take from the population, the \(\hat\beta_1\) you calculated should not fluctuate much from the mean \(\beta_1\), indicating that \(\beta_1\) and \(\hat\beta_1\) are quite “close to each other”.
But here is the catch yet again, how small is small? If for example, \(\hat{\beta_1} = 0.5\) but if \(\text{SE}(\hat{\beta_1}) = 0.499\), then this standard error is not small relative to the value of \(\hat{\boldsymbol{\beta}}\). \(\hat{\beta_1}\). One should understand in a rough sense that the standard error of \(\hat{\boldsymbol{\beta}}\) is the average amount that this particular \(\hat{\boldsymbol{\beta}}\) differs from the actual value of \(\boldsymbol{\beta}\). So if for example, the above example says that the average amount that this \(\hat{\beta_1}\) differs from the real \(\beta_1\) is 0.499, and this is not very promising because it means that our real \(\beta_1\) could be \(0.5-0.499 = 0.001\), which is very close to \(0\), we do not really feel safe about our \(\hat{\beta_1}\) since it can still suggest that our real \(\beta_1\) is near 0 and we cannot reject the null hypothesis that \(\beta_1 = 0\).
Conversely, if our standard error of \(\hat{\beta_1}\) is very large, say equals to 10000, this does not necessarily mean our \(\hat{\beta_1}\) is an inaccurate estimate of \(\beta_1\), because if our \(\beta_1\) is so large relative to 10000, say our \(\beta_1 = 1000000000000\), then this standard error is small relatively and we still have strong evidence to reject the null hypothesis. In a similar vein as the previous example, on average, we should expect our \(\beta_1\) to be around \(1000000000000 \pm 10000\), which is nowhere close to 0.
So we also must find a metric to calculate how small is small, or conversely, how big is big. Therefore, to understand that if \(\text{SE}(\hat{\beta_1}) <<< \hat{\beta_1}\), that is, standard error of the estimator \(\hat{\beta_1}\) is way smaller than \(\hat{\beta_1}\), then it is safe to say that our \(\hat{\beta_1}\) provides strong evidence that the real parameter is non-zero as well.
For example, if \(\hat{\beta_1} = 0.5\) and \(\text{SE}(\hat{\beta_1}) = 0.0001\), then even though \(\hat{\beta_1}\) is quite near \(0\), we can still feel confident to say that the real parameter \(\beta_1\) is not 0, simply because our estimate \(\hat{\beta_1}\) has such a small standard error/variation that it is very unlikely for our \(\beta_1\) to be 0.
What I have described above is merely an intuition, talk is cheap and we need to use scientific methods to quantify it. To quantify what I have said above, we use t-statistics to calculate the number of standard deviations that \(\hat{\beta_1}\) is away from \(0\). In fact the formula allows any number, not limited to 0.
T-Statistics#
In statistics, the t-statistic is the ratio of the difference of the estimated value of a true population parameter from its hypothesized value to its standard error. A good intuitive of explanation of t-statistics can be read here.
Let \(\hat{\boldsymbol{\beta}}\) be an estimator of \(\boldsymbol{\beta}\) in some statistical model. Then a t-statistic for this parameter \(\boldsymbol{\beta}\) is any quantity of the form
where \(\boldsymbol{\beta}_H\) is the value we want to test in the hypothesis. By default, statistical software sets \(\boldsymbol{\beta}_H = 0\).
In the regression setting, we further take note that the t-statistic for each individual coefficient \(\hat{\beta}_i\) is given by
If our null hypothesis is really true, that \(\beta_1=0\), then if we calculate our t-value to be 0, then we can understand it as the number of standard deviations that \(\hat{\beta}_1\) is 0, which means that \(\hat{\beta}_1\) is 0. This might be hard to reconcile at first, but if we see the formula of the t-statistics, and that by definition we set \(\beta_H=0\), then it is apparent that if \(t_{\hat{\beta}}=0\), it forces the formula to become \(t_{\hat{\beta}}=0=\dfrac{\hat{\beta}-0}{\text{SE}(\hat{\beta})} \Longrightarrow \hat{\beta}=0\) ; even more concretely with an example, we replace \(\beta_{H}\) with our favorite true population parameter \(\beta_1\) and \(\hat{\beta}\) with \(\hat{\beta}_1\), then it just means that if \(\beta_1\) were really \(0\), i.e. no relationship of \(y\) and \(x_1\), and if we also get \(t_{\hat{\beta}_1}\)to be 0 as well (To re-explain this part as a bit cumbersome). In which case we accept the null hypothesis; on the other hand, if our t-value is none-zero, it means that \(\hat{\beta}_1 \neq 0\).
Consequently, we can conclude that greater the magnitude of \(|t|\) (\(t\) can be either positive or negative), the greater the evidence to reject the null hypothesis. The closer \(t\) is to 0, the more likely there isn’t a significant evidence to reject the null hypothesis.
Implementing T-Statistics#
To find the t-value of \(\hat{\beta_1}\), we need to first know what is the standard error of \(\hat{\beta_1}\), which is \(\text{SE}(\hat{\mathbf{\beta_1}})\). The formula is given by
But since we do not know the value of the population variance \(\sigma^2\) of the error term, we estimate it with
where \(N\) is the number of samples, \(D\) is the number of features.
The python code is implemented as follows, we will use sklearn’s LinearRegression to find the parameters \(\hat{\beta_0}\) and \(\hat{\beta_1}\), and then we will use the formula above to find the standard error of \(\hat{\beta_1}\), and then we will use the formula of t-statistics to find the t-value of \(\hat{\beta_1}\).
Show code cell source
1X = X.to_numpy()
2X = X.reshape(-1, 1)
3y = y.to_numpy()
4
5N, D = X.shape
6print(f"Number of samples: {N}")
7print(f"Number of features: {D}")
8
9X_with_intercept = np.hstack((np.ones((N, 1)), X))
10print(X_with_intercept.shape)
11
12# Instantiate and fit the LinearRegression model
13lr = LinearRegression()
14lr.fit(X, y)
15
16# Predict using the fitted model
17y_pred = lr.predict(X)
18
19# Compute the residual sum of squares (RSS)
20rss = np.linalg.norm(y - y_pred) ** 2
21# Compute the sigma square estimate
22sigma_square_hat = rss / (N - (D + 1))
23# Compute the variance-covariance matrix
24var_beta_hat = sigma_square_hat * np.linalg.inv(np.dot(X_with_intercept.T, X_with_intercept))
25
26# Print the standard errors and t-values for each coefficient
27for i in range(D + 1):
28 standard_error = var_beta_hat[i, i] ** 0.5 # standard error for beta_0 and beta_1
29 print(f"Standard Error of (beta_hat[{i}]): {standard_error}")
30
31 # Get the coefficient value (beta_hat)
32 coef_value = lr.intercept_ if i == 0 else lr.coef_[0]
33 t_values = coef_value / standard_error
34 print(f"t_value of (beta_hat[{i}]): {t_values}")
35
36 print("━" * 60)
37 print("━" * 60)
Number of samples: 100
Number of features: 1
(100, 2)
Standard Error of (beta_hat[0]): 2442.4808292051985
t_value of (beta_hat[0]): 46.845211452439884
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Standard Error of (beta_hat[1]): 41.81741692793702
t_value of (beta_hat[1]): 22.997689705070346
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Well, we are only interested in the t-value of \(\hat{\beta_1}\), which shows a value of 22. Quoting from the author Jim Frost’s book, he mentioned that the tricky thing about t-values is that they are a unitless statistic, which makes them difficult to interpret on their own. We performed a t-test and it produced a t-value of 38.36. What does this t-value mean exactly? We know that the sample mean doesn’t equal the null hypothesis value because this t-value doesn’t equal zero. However, we don’t know how exceptional our value is if the null hypothesis is correct.
This is why we need to look at the P-values of the t-test. But before that, we look at t-distributions first.
T-Distributions#
How T-distribution is formed:
Define our null and alternative hypothesis. In Simple Linear Regression, we simply set:
\[\begin{split} \begin{aligned} & H_0: &\beta_1 &= 0 \\ & H_{A}: &\beta_1 &\neq 0 \end{aligned} \end{split}\]Determine the test statistic that is most suitable for this parameter \(\beta_1\). Note that \(\beta_1\) is actually a constant and not a random variable, and we cannot know the distribution of \(\beta_1\) anyways since population is unknown. However, we can make use of the OLS estimator of \(\beta_1\) to draw inferences about it. So although we do not know \(\beta_1\) we are able to derive the sampling distribution of \(\hat{\beta_1}\) which we have shown in the first section to be:
\[ \hat{\boldsymbol{\beta}} \sim N\left(\boldsymbol{\beta}, \hat{\sigma}^2(\mathbf{X}^T\mathbf{X})^{-1}\right) \]
We could jolly well define \(\hat{\beta_1}\) to be our test statistic and calculate \(P(\hat{\beta_1} \geq B_H)\) where \(B_H\) is the hypothesis we want to test, if not for the fact that we do not even know the value of \(\sigma^2\) - which we desperately need because it appeared in the variance of \(\hat{\beta_1}\). So this is the reason why we need to use an equivalent test statistic:
This means that if our \(\hat{\beta_1}\) follows a normal distribution of \(\hat{\boldsymbol{\beta}} \sim N\left(\boldsymbol{\beta}, \hat{\sigma}^2(\mathbf{X}^T\mathbf{X})^{-1}\right)\), then an equivalent distribution is \(t_{\hat{\mathbf{\beta_1}}} \sim t(df)\).
So it is clear that for any \(a, b \in \mathbb{R}\), finding \(P(a \leq \hat{\beta_1} \leq b)\) is the same as finding
So finally, we have formed a sampling distribution of t-statistics, hinged on the assumption that our null hypothesis is true, \(\beta_1 = 0\) (this is important).
Jim Statistics provides an intuitive idea.
P-Values#
We use the resulting test statistic to calculate the p-value. As always, the p-value is the answer to the question “how likely is it that we’d get a test statistic \(t_{\hat{\boldsymbol{\beta}}}\) as extreme as we did if the null hypothesis were true?” The p-value is determined by referring to a t-distribution with \(m-(n+1) = m-2\) degrees of freedom where we recall that \(m\) is the number of data, and \(n\) is the number of variables. The \(n+1\) is because we are actually fitting 2 parameters, so we add on 1 intercept term which has a dummy variable \(x_0\).
Finally, we make a decision:
If the p-value is smaller than the significance level \(\alpha\), we reject the null hypothesis in favor of the alternative. We conclude “there is sufficient evidence at the \(\alpha\) level to conclude that there is a linear relationship in the population between the predictor x and response y.”
If the p-value is larger than the significance level \(\alpha\), we fail to reject the null hypothesis. We conclude “there is not enough evidence at the \(\alpha\) level to conclude that there is a linear relationship in the population between the predictor x and response y.”
Let us implement our p-values.
Show code cell source
1X = X.reshape(-1, 1)
2N, D = X.shape
3
4lr = LinearRegression()
5lr.fit(X, y)
6
7y_pred = lr.predict(X)
8
9X_with_intercept = np.hstack((np.ones((N, 1)), X))
10
11# RSE = sqrt(RSS/(m-n))
12# thus, sigma square estimate is RSS/(m-n)
13sigma_square_hat = np.linalg.norm(y - y_pred) ** 2 / (N - (D + 1))
14var_beta_hat = sigma_square_hat * np.linalg.inv(np.dot(X_with_intercept.T, X_with_intercept))
15
16ols_parameters = [lr.intercept_] + list(lr.coef_)
17
18for i in range(D + 1):
19 standard_error = var_beta_hat[i, i] ** 0.5 # standard error for beta_0 and beta_1
20 print(f"Standard Error of (beta_hat[{i}]): {standard_error}")
21
22 t_values = ols_parameters[i] / standard_error
23 print(f"t_value of (beta_hat[{i}]): {t_values}")
24
25 p_values = 1 - stats.t.cdf(abs(t_values), df=X.shape[0] - (X.shape[1] + 1))
26 print(f"p_value of (beta_hat[{i}]): {p_values}")
27
28 print("━" * 60)
29 print("━" * 60)
Standard Error of (beta_hat[0]): 2442.4808292051985
t_value of (beta_hat[0]): 46.845211452439884
p_value of (beta_hat[0]): 0.0
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Standard Error of (beta_hat[1]): 41.81741692793702
t_value of (beta_hat[1]): 22.997689705070346
p_value of (beta_hat[1]): 0.0
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
We easily use python to calculate the statistics for us, as shown above.
Because the p-value is so small (usually less than \(0.05\), this means that if our null hypothesis was actually true that \(\beta_1 = 0\), then there is only a \(0.0\%\) chance to get this \(t = 38.348\) value. In other words, it is unlikely to observe such a substantial association between the predictor and the response due to chance, in the absence of any real association between the predictor and the response. We can reject the null hypothesis and conclude that \(\beta_1\) does not equal 0. There is sufficient evidence, at the \(\alpha = 0.05\) level, to conclude that there is a linear relationship in the population between house area and the sale price.
Similarly, we can see the p-value for \(\hat{\beta_0}\) to be less than \(0.05\) as well. Consequently, we conclude that \(\beta_0 \neq 0\) and \(\beta_1 \neq 0\).
Since the above is a self implemented function, it is always good to check with the statsmodels.api from python to check if I am correct.
Show code cell source
1OLS(y, X_with_intercept).fit().summary()
| Dep. Variable: | y | R-squared: | 0.844 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.842 |
| Method: | Least Squares | F-statistic: | 528.9 |
| Date: | Tue, 17 Dec 2024 | Prob (F-statistic): | 2.81e-41 |
| Time: | 09:44:38 | Log-Likelihood: | -1082.2 |
| No. Observations: | 100 | AIC: | 2168. |
| Df Residuals: | 98 | BIC: | 2174. |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 1.144e+05 | 2442.481 | 46.845 | 0.000 | 1.1e+05 | 1.19e+05 |
| x1 | 961.7040 | 41.817 | 22.998 | 0.000 | 878.719 | 1044.689 |
| Omnibus: | 0.135 | Durbin-Watson: | 2.166 |
|---|---|---|---|
| Prob(Omnibus): | 0.935 | Jarque-Bera (JB): | 0.038 |
| Skew: | 0.047 | Prob(JB): | 0.981 |
| Kurtosis: | 2.992 | Cond. No. | 117. |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
We see the t and p values coincide.
The Pandora Box of Confidence Intervals, P-values and Hypothesis Testing#
The focus of this post is not to go into details on how to interpret the coefficients using statistical methods. As I’ve mentioned, regression analysis in itself can be one whole undergraduate module spanning more than 1 term/semester. To have a more thorough understanding, I would recommend reading the regression chapter in An Introduction to Statistical Learning by Gareth James, Daniela Witten, Trevor Hastie and Robert Tibshirani.
Time Complexity#
Time Complexity is an important topic, you do not want your code to run for 1 billion years, and therefore, an efficient code will be important to businesses. That is also why Time Complexity questions are becoming increasingly popular in Machine Learning and Data Science interviews!
The Linear Algorithm that we used here simply uses matrix multiplication. We will also ignore the codes that are of constant time O(1). For example, self.coef_=None in the constructor is O(1) and we do not really wish to consider this in the grand scheme of things.
What is the really important ones are in code lines 37–40. Given X to be a m by n matrix/array, where m is the number of samples and n the number of features. In addition, y is a m by 1 vector. Refer to this Wikipedia Page for a handy helpsheet on the various time complexity for mathematical operations.
Line 37: np.dot(X.T,X) In the dot product, we transpose the m × n matrix to become n × m, this operation takes O(m × n) time because we are effectively performing two for loops. Next up is performing matrix multiplication, note carefully that np.dot between two 2-d arrays does not mean dot product, instead they are matrix multiplication, which takes O(m × n²) time. The output matrix of this step is n× n.
Line 38: Inverting a n × n matrix takes n³ time. The output matrix is n × n.
Line 39: Now we perform matrix multiplication of n × n and n × m, which gives O(m × n²), the output matrix is n × m.
Line 40: Lastly, the time complexity is O(m × n).
Adding them all up gives you O(2mn+2mn²+n³) whereby simple triangle inequality of mn<mn² implies we can remove the less dominant 2mn term. In the end, the run time complexity of this Linear Regression Algorithm using Normal Equation is O(n²(m+n)). However, you noticed that there are two variables in the bigO notation, and you wonder if we can further reduce the bigO notation to a single variable? Well, if the number of variables is small, which means n is kept small and maybe constant, we can reduce the time complexity to O(m), however, if your variables are increasing, then your time complexity will explode if n → ∞.
References and Further Readings#
Mohri, Mehryar, Rostamizadeh Afshi and Talwalkar Ameet. Foundations of Machine Learning. The MIT Press, 2018.
Murphy, Kevin P. “Chapter 21.3. K-Means Clustering.” In Probabilistic Machine Learning: An Introduction. MIT Press, 2022.
Hal Daumé III. “Chapter 3.4. K-Means Clustering.” In A Course in Machine Learning, January 2017.
Hal Daumé III. “Chapter 15.1. K-Means Clustering.” In A Course in Machine Learning, January 2017.
Bishop, Christopher M. “Chapter 9.1. K-Means Clustering.” In Pattern Recognition and Machine Learning. New York: Springer-Verlag, 2016.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. “Chapter 12.4.1. K-Means Clustering.” In An Introduction to Statistical Learning: With Applications in R. Boston: Springer, 2022.
Hastie, Trevor, Tibshirani, Robert and Friedman, Jerome. “Chapter 14.3. Cluster Analysis.” In The Elements of Statistical Learning. New York, NY, USA: Springer New York Inc., 2001.
Raschka, Sebastian. “Chapter 10.1. Grouping objects by similarity using k-means.” In Machine Learning with PyTorch and Scikit-Learn.
Jung, Alexander. “Chapter 8.1. Hard Clustering with K-Means.” In Machine Learning: The Basics. Singapore: Springer Nature Singapore, 2023.
Vincent, Tan. “Lecture 17a.” In MA4270 Data Modelling and Computation.
Normal Equation (ML Wiki) Wholesome and Mathematically Rigorous
Linear Regression Assumptions by Jeff Macaluso from Microsoft
Stanford’s STATS203 class - Consider downloading them before it’s gone
Feature Scaling does not affect Linear Regressions’ validity of Coefficients