Stage 3. Data Pipeline (Data Engineering and DataOps)#
Table of Contents#
As we transition from the project scoping phase, where we framed the problem and identified key metrics and components, we now take a look at the DataOps phase. Even though data engineering and data operations are a whole different beast, we can at least look into the basic lifecycle of it - so at least when you converse with your precious data engineers, you know what they are talking about instead of acting like you know.
Intuitively and simply put (data engineers don’t bash me), the data operations phase involves collecting, integrating, transforming, and managing data. Here, we identify the data sources, ensure their quality, preprocess them for downstream tasks such as machine learning, and set up the operations needed for efficient handling. Additionally, this phase involves setting up sophisticated data pipelines that ensure efficient, reliable, and scalable data flow across different stages, from ingestion to modeling. This involves leveraging technologies like distributed systems and cloud services to manage the vast volumes of data that modern enterprises typically handle.
I won’t act as if I know the in-depth details of data engineering (yes my data engineers helped me load terabytes of data for pretraining and without them I am jobless), but this post is to draw some reference from those who know. So, let’s dive in.
Data Engineering In Machine Learning#
Machine learning models require require data. And from the GPT-2 paper named Language Models are Unsupervised Multitask Learners, the authors mentioned that one major key to the success of their model is the quantity and quality of the data used for training. They have to preprocess the data before feeding it into the model, and imagine the amount of data engineering work behind the scenes in order to automate and scale the process.
From data collection, data preprocessing, feature engineering, data transformation, data validation, data versioning, and data pipeline setup, data engineering is not just about cleaning the data, you have to ensure that the data is accessible easily and efficiently.
They establish data pipelines that automate the flow of data from source to destination, allowing for continuous integration and real-time processing. So yes, not only is MLOps all the hype, but DataOps is also a critical part of the machine learning lifecycle.
A Naive DataOps Pipeline#
In this section we outline a very naive and simple workflow of a data engineering pipeline. This is meant to give you a high-level overview of the process, and by no means encapsulates the complexity of a real-world data engineering workflow. Things like big data paradigms like Hadoop, Spark, and distributed systems are not covered here.
DataOps’s iterative process consists of several stages:
Data Collection: Identifying the relevant data sources and collecting the data.
Data Ingestion/Integration: This stage consists of two major parts:
Data Extraction: Extracting the collected data from various sources.
Data Loading: Loading the extracted data into a centralized storage such as a data warehouse, data lake, or lakehouse.
Data Transformation: Transforming the data into a format suitable for downstream tasks. This stage may include cleaning, aggregating, or restructuring the data.
Data Validation: A crucial step to ensure the accuracy and quality of the data. Validation techniques can be applied in parallel with the data transformation stage or immediately after loading the raw data. By performing this step, one guarantees that the data adheres to the defined standards and is suitable for further processing and analysis.
CI/CD Integration: Implementing Continuous Integration/Continuous Deployment (CI/CD) to automate and streamline the data workflow for the aforementioned stages.
These stages can be organized into a data pipeline. A data pipeline is a set of data processing elements connected in series, where the output of one element becomes the input of the next. Elements may be executed in parallel or series, and the pipeline ensures that data transitions smoothly through the stages, maintaining consistency, efficiency, and scalability.
Architecture#
Here’s a high-level overview of the data engineering workflow, in the form of a diagram:
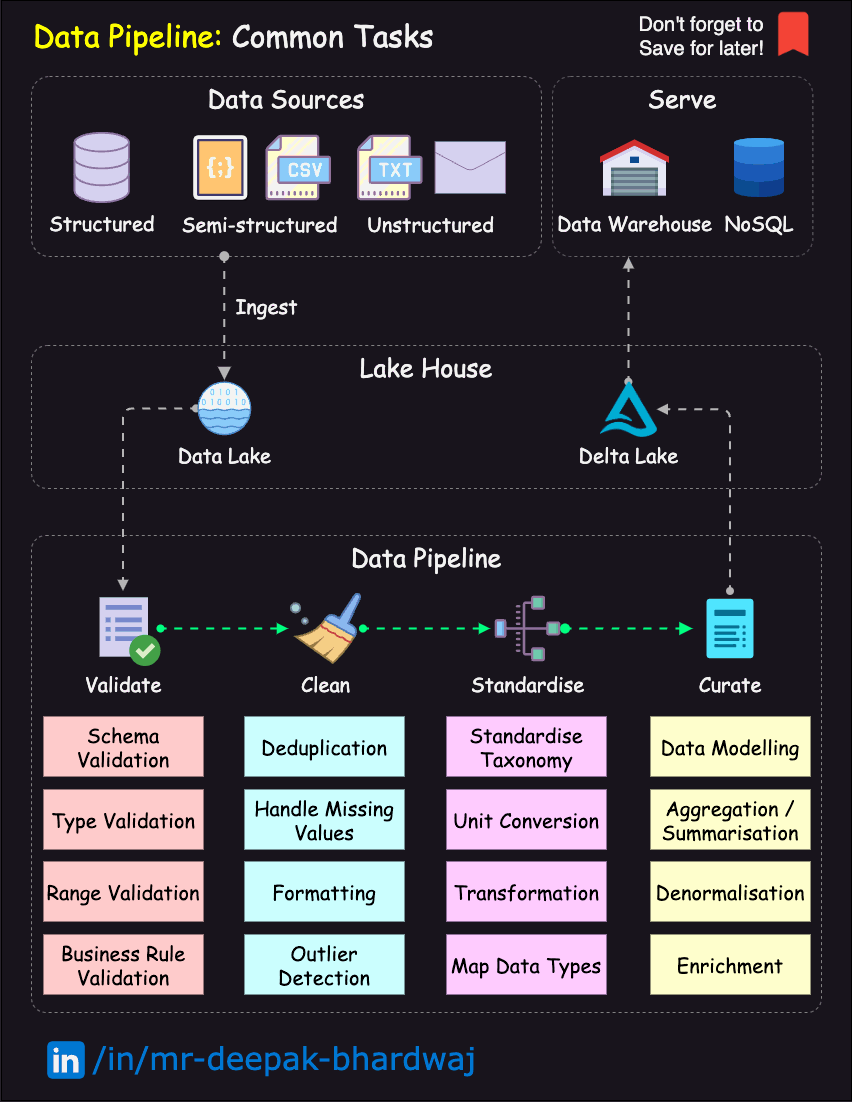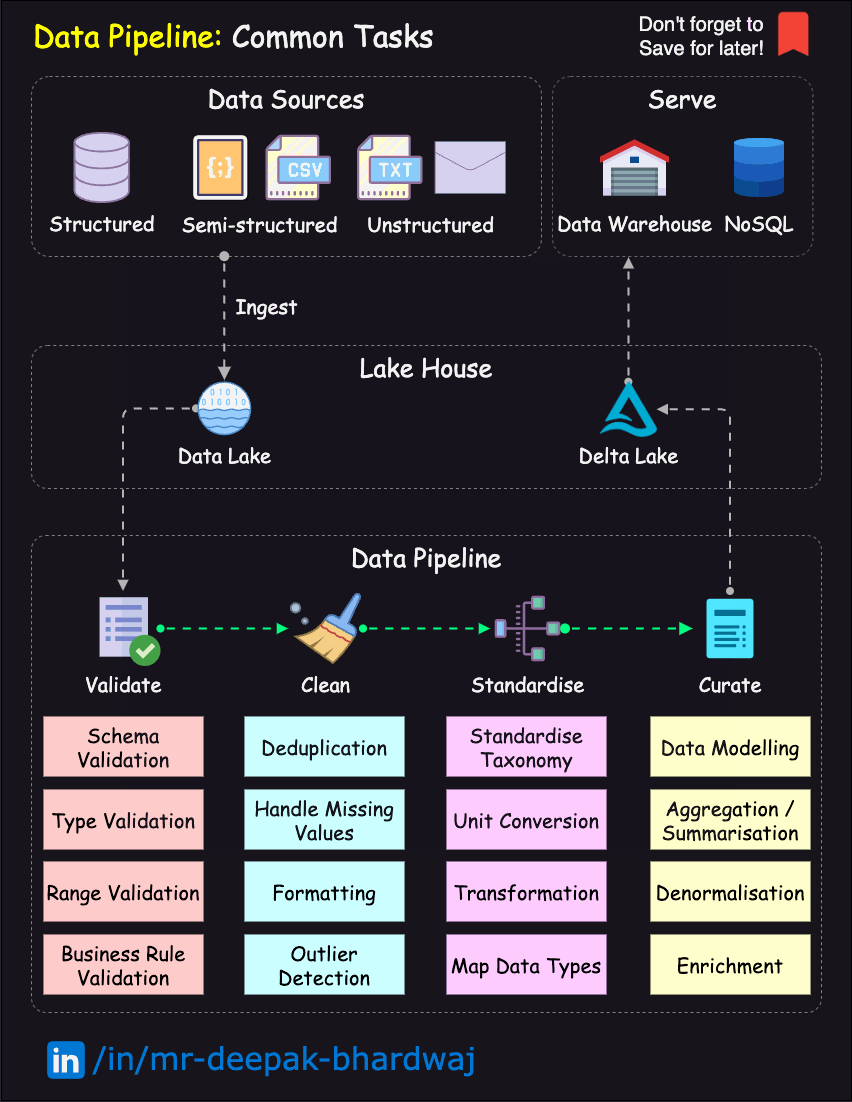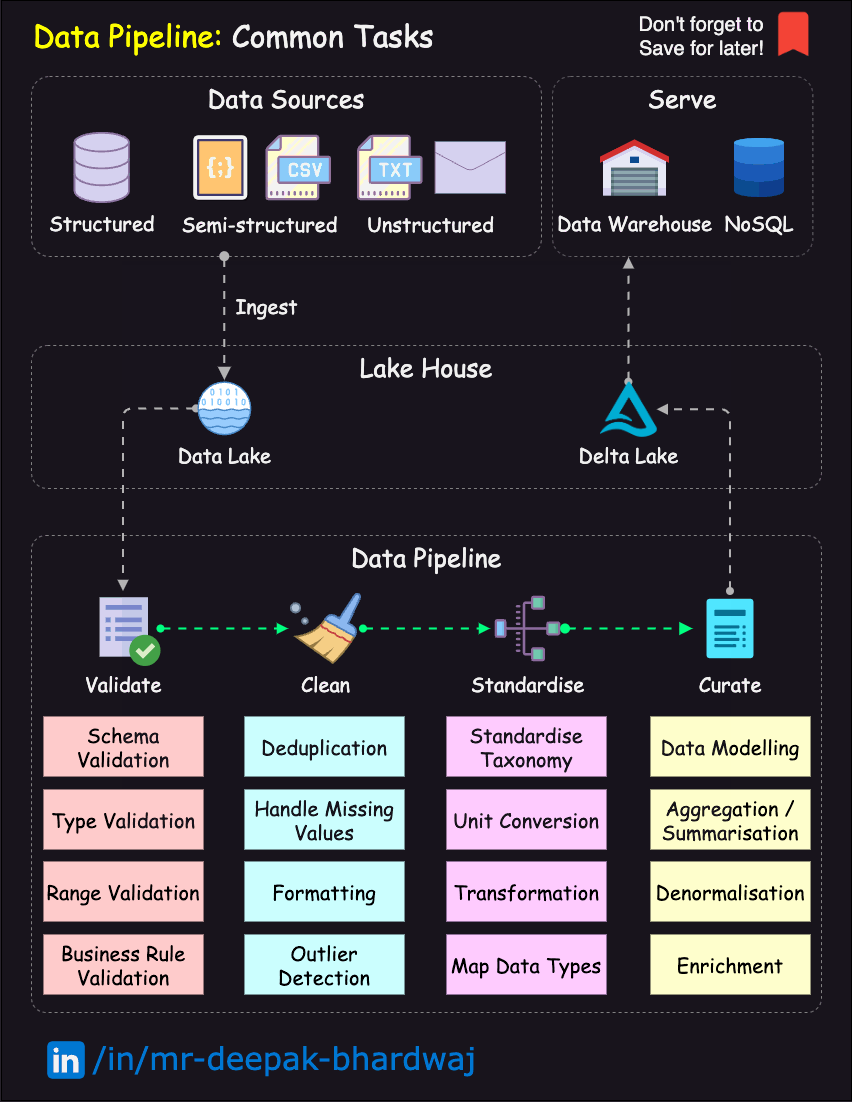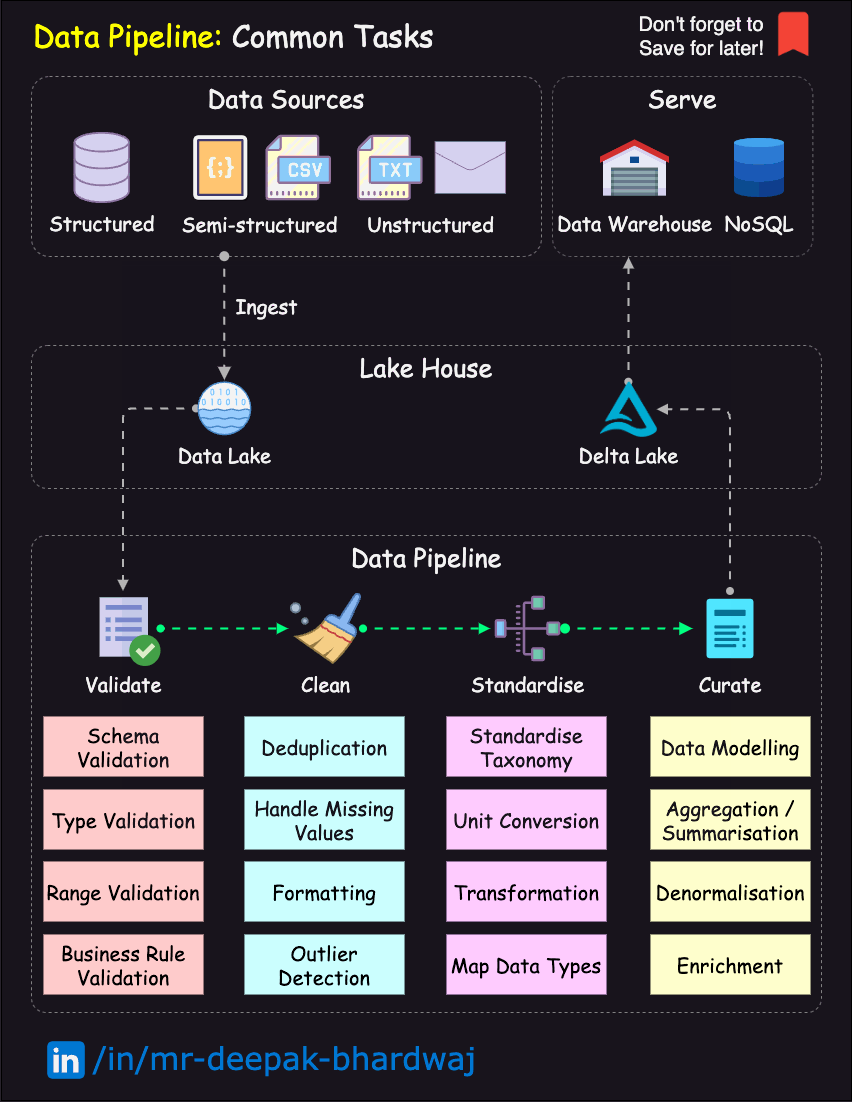
Fig. 48 DataOps Lifecycle.#
Image Credit: Deepak
We will now give a grossly simplified example of a data engineering workflow. This by no means represent the actual (and often much more complex) workflow in the industry, however, it should give you a good idea of the general process.
Staging/Experiment/Development#
Legends:
Staging: The staging environment is where the code is deployed for testing purposes. It is a replica of the production environment where the code is tested before it is deployed to production.
Production: The production environment is where the code is deployed for production use. It is the environment where the code is used by the end users.
There are many more environments in a typical software development lifecycle, like QA, UAT, etc. However, for the sake of simplicity, we will focus on the staging and production environments.
Step 1. Data Extraction#
Source data is identified and extracted from various internal and external databases and APIs.
Data is extracted using either full or incremental refreshes, depending on the source system.
The data can be extracted via pure code level such as using Python, or using modern tech stacks such as Airbyte, FiveTran or orchestration tools such as Airflow.
A sample python DAG for this step is as follows:
from pydantic import BaseModel
from abc import ABC, abstractmethod
from typing import Optional, Any
class Config(BaseModel):
...
class Logger(BaseModel):
...
class Connection(BaseModel):
...
class Metadata(BaseModel):
...
class Extract:
def __init__(
self, cfg: Config, logger: Logger, connection: Connection, metadata: Metadata
) -> None:
self.cfg = cfg
self.logger = logger
self.connection = connection
self.metadata = metadata
def extract_from_connection(self) -> None:
"""Extract data from data warehouse."""
self.logger.info(f"Extracting data from {self.connection.name}...")
def run(self) -> None:
"""Run the extract process."""
self.extract_from_connection()
where
cfg,loggerandmetadataare the configuration, logger and metadata objects respectively.connectionis the connection object that represents the data source. It can be API, database, etc.
Step 2. Data Loading to Staging Lake#
Let’s assume that we want to extract our data from a remote API and load it to a staging layer in Google Cloud Storage (GCS), where the GCS serves as the staging data lake.
Let’s have a look a templated DAG for this step.
First, we define a base class for the load process.
class Validator(ABC):
@abstractmethod
def validate(self, data: Any) -> bool:
"""Validates the data. Returns True if valid, False otherwise."""
class DVC(ABC):
@abstractmethod
def commit(self, message: str) -> None:
"""Commits the changes to the DVC repository."""
class Load(ABC):
def __init__(
self,
cfg: Config,
logger: Logger,
metadata: Metadata,
dvc: Optional[DVC] = None,
validator: Optional[Validator] = None,
) -> None:
self.cfg = cfg
self.logger = logger
self.metadata = metadata
self.dvc = dvc
self.validator = validator
@abstractmethod
def load_to_staging(self) -> None:
"""Load data to staging."""
@abstractmethod
def load_to_production(self) -> None:
"""Load data to production."""
def run(self, is_staging: bool = True) -> None:
"""Run the load stage."""
self.logger.info("Running load stage")
self.load_to_staging() if is_staging else self.load_to_production()
self.logger.info("Load stage complete")
Then, we define a class that inherits from the base class.
class LoadToLake(Load):
def load_to_staging(self) -> None:
"""Load data to staging."""
self.logger.info(f"Loading data to staging {self.cfg.staging_lake}")
def load_to_production(self) -> None:
"""Load data to production."""
self.logger.info(f"Loading data to production {self.cfg.production_lake}")
Extracted data from step 1 is loaded into a dedicated staging area within Google Cloud Storage (GCS). This process serves as the initial raw data checkpoint, providing an immutable storage layer for unprocessed data. This approach to storing raw data helps maintain data integrity throughout the pipeline.
The data is stored in a structured format, for instance, in the form of:
staging/raw_{table_name}/created_at={YYYY-MM-DD:HH:MM:SS:MS}`where
stagingis the staging layer in GCS.raw_table_nameis the name of the table that you intend to store later. Simply put, it is the name of the dataset.
This structure allows for easy tracking of the data’s origin and timestamp, adhering to the common partitioning scheme used in data storage. We can also add commit hash if need be, but as we shall see shortly, if we have a versioning tool like DVC, we can use that to maintain the data’s lineage.
Even though the data is stored such that we can easily reference the data’s origin and timestamp, there is a need to maintain a detailed record of the data’s lineage. This is where the metadata comes in. The metadata contains information such as the data’s origin, timestamp, and other essential details such as the data’s schema.
Furthermore, modern data versioning tools such as DVC (Data Version Control) can be used to maintain a detailed record of the data’s lineage, ensuring that changes to the data can be tracked and managed in a reproducible manner.
What is the rationale in storing the data in GCS?
Raw Data Checkpoint: GCS serves as a storage layer for raw, unprocessed data. This creates a checkpoint where the data is unaltered and can be reverted to if needed.
Flexibility: Storing data in GCS provides flexibility in data formats and allows for decoupling of storage and compute. It can serve various downstream applications that might require raw data.
Cost-Effective: GCS typically provides a more cost-effective solution for storing large volumes of data, especially when long-term storage is needed.
Immutable Storage Layer: By providing an immutable storage layer, GCS ensures that the original raw data remains unaltered, maintaining data integrity.
Interoperability: GCS can serve multiple environments and tools, not just BigQuery, so it’s a general-purpose storage solution.
Step 3. Loading Data to Staging Warehouse#
Now, once we have the data in the staging GCS, we can load it to staging BigQuery. This is done using the following.
class LoadToWarehouse(Load):
def load_to_staging(self) -> None:
"""Load data to staging."""
self.logger.info(f"Loading data to staging {self.cfg.staging_warehouse}")
def load_to_production(self) -> None:
"""Load data to production."""
self.logger.info(f"Loading data to production {self.cfg.production_warehouse}")
The data in the staging GCS is loaded into Google BigQuery for more advanced processing and analysis. We are assuming the data is structured and ready for loading into BigQuery.
Data can be loaded using both write and append modes, allowing for incremental refreshes.
Metadata such as
created_atandupdated_attimestamps are added to maintain a detailed record of the data’s lineage.As BigQuery’s primary key system may have limitations, one needs to be careful to ensure that there are no duplicate records in the data.
The path name of the data in GCS is used as the table name in BigQuery. For instance, if the data is stored in the following path:
staging/raw_{table_name}/created_at={YYYY-MM-DD:HH:MM:SS:MS}`then the table name in BigQuery will be
staging/raw_{table_name}.
What is the rationale in storing the data in BigQuery, the staging analytics layer?
Advanced Processing & Analysis: BigQuery is designed for performing complex queries and analytics. Loading data into BigQuery allows you to leverage its full analytical capabilities.
Optimized Query Performance: BigQuery provides optimized query performance, making it suitable for interactive and ad-hoc queries, dashboards, and reports.
Step 4. Data Validation After Extraction and Load#
Once the data is extracted and loaded into the staging area in GCS or BigQuery, a preliminary data validation process is conducted.
This may include checking for the presence and correctness of key fields, ensuring the right data types, checking data ranges, verifying data integrity, and so on.
If the data fails the validation, appropriate error handling procedures should be implemented. This may include logging the error, sending an alert, or even stopping the pipeline based on the severity of the issue.
Recall earlier in our Load base class, there is a validator in the
constructor? This is where we can specify the validator to use for the data
validation process.
We can define a validation interface (an abstract class in Python) that will enforce the structure of all validators.
class Validator(ABC):
@abstractmethod
def validate(self, data: Any) -> bool:
"""Validates the data. Returns True if valid, False otherwise."""
Then we implement our own validator by inheriting from the Validator
interface.
class MySpecificValidator(Validator):
def validate(self, data: Any) -> bool:
"""Add logic here to check data's correctness, data types, etc."""
return is_valid
Within the Load class, you can call the validate method of the provided
validator instance at the appropriate stage of loading. Here’s an example that
adds a validation step after loading to staging:
class Load(ABC):
def load_to_staging(self) -> None:
"""Load data to staging."""
# Loading logic here...
self.logger.info(f"Loading data to staging {self.cfg.staging_dir}")
# Validate the data
if self.validator:
is_valid = self.validator.validate(data) # assuming data is what you want to validate
if not is_valid:
self.logger.error("Validation failed for staging data")
# Additional error handling logic like raise etc.
return
self.logger.info("Load stage to staging complete")
It’s common in the industry to see a hybrid approach where basic validation is performed at the staging lake layer (GCS), followed by more validation once the data is loaded into staging warehouse layer (BigQuery). For example, some obvious bad data can be filtered out at the GCS layer, while more complex and specific validation can be done at the BigQuery layer.
Step 5. Data Transformation#
In this step, the raw data from the staging area undergoes a series of transformation processes to be refined into a format suitable for downstream use cases, including analysis and machine learning model training. These transformations might involve operations such as:
Data Cleaning: Identifying and correcting (or removing) errors and inconsistencies in the data. This might include handling missing values, eliminating duplicates, and dealing with outliers.
Joining Data: Combining related data from different sources or tables to create a cohesive, unified dataset.
Aggregating Data: Grouping data by certain variables and calculating aggregate measures (such as sums, averages, maximum or minimum values) over each group.
Structuring Data: Formatting and organizing the data in a way that’s appropriate for the intended use cases. This might involve creating certain derived variables, transforming data types, or reshaping the data structure.
It’s important to note that the transformed data at this stage is intended to be a high-quality, flexible data resource that can be leveraged across a range of downstream use cases - not just for machine learning model training and inference. For example, it might also be used for business reporting, exploratory data analysis, or statistical studies.
By maintaining a general-purpose transformed data layer, the pipeline ensures that a broad array of users and applications can benefit from the data cleaning and transformation efforts, enhancing overall data usability and efficiency within the organization.
class Transformation:
def __init__(
self,
cfg: Config,
logger: Logger,
metadata: Metadata,
validator: Validator,
) -> None:
self.cfg = cfg
self.logger = logger
self.metadata = metadata
self.validator = validator
def clean_data(self, data: Any) -> Any:
"""Identify and correct errors and inconsistencies in the data."""
self.logger.info("Logic for handling missing values, duplicates, outliers, etc.")
return data
def join_data(self, data1: Any, data2: Any) -> Any:
"""Combine related data from different sources or tables."""
self.logger.info("Logic for joining data from multiple sources")
return joined_data
def aggregate_data(
self, data: Any, grouping_variables: List[str], aggregation_functions: Dict[Any, Any]
) -> Any:
"""Group data and calculate aggregate measures."""
self.logger.info("Logic for aggregating data")
return aggregated_data
def structure_data(self, data: Any) -> Any:
"""Format and organize the data for intended use cases."""
self.logger.info("Logic for creating derived variables, transforming data types, reshaping structure, etc.")
return structured_data
def transform(self, data: Any) -> Any:
"""Execute the entire transformation process."""
self.logger.info("Starting data transformation")
data = self.clean_data(data)
# If more than one data source needs to be joined
# data = self.join_data(data1, data2)
data = self.aggregate_data(data, grouping_variables, aggregation_functions)
data = self.structure_data(data)
self.logger.info("Data transformation complete")
if self.validator:
is_valid = self.validator.validate(data)
if not is_valid:
self.logger.error("Validation failed for transformed data")
return # or raise
return data
Step 6. Data Validation After Transformation#
In step 5, we have another validator instance that validates the transformed
data. The validator instance is passed to the Transformation class in the
constructor.
if self.validator:
is_valid = self.validator.validate(data)
if not is_valid:
self.logger.error("Validation failed for transformed data")
return
After the data transformation process, another round of validation is carried out on the transformed data.
This may involve checking the output of the transformation against expected results, ensuring the data structure conforms to the target schema, and performing statistical checks (e.g., distributions, correlations, etc.).
If the transformed data fails the validation, appropriate steps are taken just like after extraction.
By now, we should already be able to tell that the data validation process is an integral part of the data pipeline. It’s not just a one-time check at the beginning of the pipeline, but rather a continuous process that occurs at multiple stages throughout the pipeline. Phew, so much work!
Step 7. Load Transformed Data to Staging GCS and BigQuery#
After the data transformation and validation, the resulting data is loaded back into the staging environment. This involves both Google Cloud Storage (GCS) and BigQuery.
Staging GCS: The transformed data is saved back into a specific location in the staging GCS. This provides a backup of the transformed data and serves as an intermediate checkpoint before moving the data to the production layer.
Staging BigQuery: The transformed data is also loaded into a specific table in the staging area in BigQuery. Loading the transformed data into BigQuery allows for quick and easy analysis and validation of the transformed data, thanks to BigQuery’s capabilities for handling large-scale data and performing fast SQL-like queries.
This step of loading the transformed data back into the staging GCS and BigQuery is very similar to the earlier loading step. The
Loadclass can be reused for this step as well.
Step 8. (Optional) Writing a DAG to Automate the Pipeline#
The whole step from 1 to 7 can be wrapped in a DAG.
This means you can use things like Airflow to orchestrate the whole process.
We can automate the code without a DAG as well, so why DAG? Here’s some reasons.
Feature |
Description |
|---|---|
Scheduling and Automation |
Airflow provides built-in scheduling options. You can define complex schedules in a standard way, allowing tasks to be run at regular intervals, on specific dates, or in response to specific triggers. Managing scheduling in a custom Python script can be more labor-intensive and error-prone. |
Parallel Execution and Resource Management |
Airflow allows for parallel execution of tasks that don’t depend on each other. It can efficiently manage resources and distribute tasks across different workers, something that can be complex and time-consuming to implement in a custom Python pipeline. |
Monitoring and Logging |
Airflow provides a user-friendly web interface that includes detailed logs, visualizations of DAG runs, task status information, and more. Building such comprehensive monitoring and logging capabilities into a custom Python pipeline would require significant development effort. |
Error Handling and Retries |
Airflow offers standard mechanisms for handling task failures, including retries with backoff, notifications, etc. Implementing similar robust error handling in a custom Python pipeline might require substantial work. |
Integration with Various Tools |
Airflow has a rich ecosystem of operators that facilitate integration with various data sources, platforms, and tools. Implementing such integrations manually in a custom Python script can be time-consuming and less flexible. |
Scalability |
Airflow is designed to run on distributed systems, making it easier to scale up as data and processing requirements grow. Building scalability into a custom Python pipeline might require extensive architectural changes. |
Airflow however is a complex tool, and if the use case is simple, it might be overkill - or one can argue if use case is simple, then the underlying DAG might be simple as well. One key thing of Airflow is the observability and monitoring capabilities it provides, which is crucial. Imagine a cronjob failing and you have no idea why, and you have to dig through logs to find out what happened.
Step 9. Containerize the DAG#
Once your DAG or python code is ready, we can containerize it and deploy it.
A templated Dockerfile can look like this:
ARG PYTHON_VERSION=3.9
ARG CONTEXT_DIR=.
ARG HOME_DIR=/pipeline-dataops
ARG VENV_DIR=/opt
ARG VENV_NAME=venv
FROM python:${PYTHON_VERSION}-slim-buster as builder
ARG CONTEXT_DIR
ARG HOME_DIR
ARG VENV_DIR
ARG VENV_NAME
WORKDIR ${HOME_DIR}
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
python3-dev && \
rm -rf /var/lib/apt/lists/*
RUN python -m venv ${VENV_DIR}/${VENV_NAME}
ENV PATH="${VENV_DIR}/${VENV_NAME}/bin:$PATH"
ARG REQUIREMENTS=requirements.txt
ARG REQUIREMENTS_DEV=requirements_dev.txt
COPY ./${CONTEXT_DIR}/${REQUIREMENTS} .
COPY ./${CONTEXT_DIR}/${REQUIREMENTS_DEV} .
RUN python3 -m pip install --upgrade pip && \
python3 -m pip install --no-cache-dir -r ${REQUIREMENTS} && \
python3 -m pip install --no-cache-dir -r ${REQUIREMENTS_DEV} && \
pip install -U gaohn-common-utils && \
pip install pydantic==2.0b3
# This is the real runner for my app
FROM python:${PYTHON_VERSION}-slim-buster as runner
ARG CONTEXT_DIR
ARG HOME_DIR
ARG VENV_DIR
ARG VENV_NAME
# Copy from builder image
COPY --from=builder ${VENV_DIR}/${VENV_NAME} ${VENV_DIR}/${VENV_NAME}
COPY --from=builder ${HOME_DIR} ${HOME_DIR}
# Set work dir again to the pipeline_training subdirectory
# Set the working directory inside the Docker container
WORKDIR ${HOME_DIR}
RUN apt-get update && \
apt-get install -y --no-install-recommends jq && \
rm -rf /var/lib/apt/lists/*
ENV PATH="${VENV_DIR}/${VENV_NAME}/bin:$PATH"
ARG GIT_COMMIT_HASH
ENV GIT_COMMIT_HASH=${GIT_COMMIT_HASH}
# Copy the rest of the application's code
COPY ${CONTEXT_DIR}/conf ${HOME_DIR}/conf
COPY ${CONTEXT_DIR}/metadata ${HOME_DIR}/metadata
COPY ${CONTEXT_DIR}/schema ${HOME_DIR}/schema
COPY ${CONTEXT_DIR}/pipeline_dataops ${HOME_DIR}/pipeline_dataops
COPY ${CONTEXT_DIR}/pipeline.py ${HOME_DIR}/pipeline.py
COPY ${CONTEXT_DIR}/scripts/docker/entrypoint.sh ${HOME_DIR}/scripts/docker/entrypoint.sh
RUN chmod -R +x ${HOME_DIR}/scripts/docker
CMD ["scripts/docker/entrypoint.sh"]
Step 10. Deploy the DAG (Staging Environment)#
After containerizing the DAG, we can deploy it. For instance, we can deploy it
to a Kubernetes cluster on a CronJob resource.
We will not go into the details of how to deploy a DAG to a somewhere like a Kubernetes cluster here - it is out of scope and can be a whole topic on its own.
Step 11. Trigger the DAG as part of a CI/CD pipeline#
Step |
Description |
Action |
Rationale |
|---|---|---|---|
Version Control |
All code related to data extraction, transformation, and loading (ETL), as well as any related testing code and configuration files, is stored in a version control system like DVC and Git. |
The developer makes and commits the necessary code changes to the version control system, such as Git. |
Facilitates collaboration, versioning, and tracking changes. This is usually the first trigger in the CI/CD pipeline. |
Trigger CI/CD Pipeline for Development |
The commit automatically triggers the development Continuous Integration/Continuous Deployment (CI/CD) pipeline. |
The commit automatically triggers the development CI/CD pipeline. |
Enables automated building and testing, ensuring that changes are immediately evaluated for compatibility and correctness. |
Continuous Integration |
When changes are pushed to the version control system, this triggers the Continuous Integration process. Things like linting, type checking, unit tests, etc. are run. |
When changes are pushed to the version control system, this triggers the Continuous Integration process. Tools such as GitHub Actions can be used to automate this process. |
The new code is merged with the main code base and automated tests are run to ensure that the changes do not break existing functionality. |
Continuous Integration: Unit and Integration Tests |
The code changes are subjected to unit tests and integration tests. |
The code changes are subjected to unit tests (testing individual components) and integration tests (testing interactions between components). |
Ensures that the code performs as expected at both the component and system levels, minimizing the risk of introducing new bugs. |
Continuous Integration: Build Image of the DAG |
Once the code level changes passed the unit and integration tests. An image of the updated DAG, containing all necessary dependencies and configurations, is built. |
Once the code level changes passed the unit and integration tests, an image of the updated DAG is built. |
The image simplifies deployment and scaling by encapsulating the entire application into a single deployable unit. At this stage, the image is test-run to ensure it works as expected. |
Continuous Integration: System Tests |
The whole Directed Acyclic Graph (DAG), packaged into an image, is tested to ensure that the entire pipeline, with the updated transformation logic, provides the correct output. |
The whole DAG, packaged into an image, is tested. |
Validates that the entire system functions correctly, confirming that changes did not inadvertently disrupt other parts of the pipeline. We usually do system test separately from unit and integration tests because it might require more resources and time. |
Continuous Deployment: Push Image to (Staging) Artifacts Registry |
The built image is pushed to a designated artifacts registry, such as Docker Hub or a private registry. |
The built image is pushed to a designated artifacts registry. |
Stores the deployable image in a centralized location, making it easily accessible for subsequent deployment stages. Allows for version control and rollback capabilities of deployed images. |
Continuous Deployment: Deploy Image to Staging Environment |
The image is deployed to the staging environment, where it is tested to ensure that it functions as expected. |
The image is deployed to the staging environment. |
Validates that the image is deployable and performs as expected in a production-like environment. |
Continuous Deployment: Performance Tests |
The data pipelines are tested under simulated production load. |
The data pipelines are tested under simulated production load. |
Identifies any performance bottlenecks or issues that could affect the data pipeline’s performance in production. |
Trigger Message to Pub/Sub |
After successful deployment in the staging environment, a message is triggered to a Pub/Sub system to notify other services or systems. |
A message is sent to a designated Pub/Sub service, such as Google Cloud Pub/Sub or Apache Kafka, to signify the completion of deployment or to kick off subsequent processes such as deployment to production environment. |
Ensures downstream systems or services are notified of the pipeline’s status, facilitating automated workflows and integrations across different parts of the infrastructure. In our example, the trigger will lead us to deploy the application to the production environment since the data pipeline is well validated and tested in the staging environment. |
Production Layer#
Step 1. Triggering the Production Deployment Pipeline#
Action:
A success message from the development pipeline in the staging environment is sent to Pub/Sub, triggering the CI/CD pipeline. The logic can be as simple as if the staging pipeline is successful, then trigger the production pipeline.
The production deployment pipeline is initiated.
A manual approval process typically confirms the deployment to production.
Rationale:
Enables automatic transition from development to production stages.
Ensures human oversight and control over what gets deployed.
Step 2. CI/CD: Deploy Image to Production Environment#
Basically, the same steps as in the staging environment, but this time the image is deployed to the production environment.
We can have some additional steps such as monitoring and feedback loops.
Monitoring and Alerting#
This step will not be covered in details as it is out of scope for this post, but will be discussed in the later stages. Monitoring is a big thing in Machine Learning because not only do we monitor for system health, we also monitor for data quality and data drift.
Once deployed, the data pipelines are continuously monitored to ensure they are functioning correctly. This can involve tracking metrics such as data quality, pipeline performance, and resource usage. Any issues that arise can trigger alerts for immediate response.
Action:
Implement ongoing monitoring for data quality and data drift.
Rationale:
Ensures continued adherence to quality standards.
Quickly detects and alerts to any changes in the data distribution, which could impact model performance or other downstream applications.
Feedback Loop#
This refers to insights from monitoring and any errors encountered in production are fed back into the development process, leading to new iterations of development, testing, and deployment.
Summary#
Typically, the movement of data from the staging layer to the production layer happens once the data has been cleaned, transformed, validated, and is deemed ready for use in downstream applications such as machine learning model training, analytics, reporting, etc. The transformed data is first validated to ensure that it meets the required quality standards. If the validation is successful, the data is moved to the production layer. The goal is to only expose clean, validated, and reliable data to end users or downstream applications.
Once the data has passed both rounds of validation, it can be loaded into the production layer in both GCS and BigQuery. At this point, the data is ready for downstream use in tasks such as model training and inference.
In the context of ML, these steps form the beginning part of our pipeline, where data is extracted, cleaned, and made ready for use in our ML models. Each step is designed to ensure the integrity and usability of the data, from extraction to querying for model training and inference.
As a reminder, this is highly simplified and the actual process can be much more complex. For example, we simply assumed GCS and BigQuery, but in reality, you might have multiple data sources and destinations and even multiple data lakes and warehouses. The key is to understand the principles and adapt them to your needs.
References and Further Readings#
Huyen, Chip. “Chapter 3. Data Engineering Fundamentals.” In Designing Machine Learning Systems: An Iterative Process for Production-Ready Applications, O’Reilly Media, Inc., 2022.
Kleppmann, Martin. “Chapter 2. Data Models and Query Languages.” In Designing Data-Intensive Applications. Beijing: O’Reilly, 2017.