Stage 3.2. Data Model and Storage#
As we see shortly in the next few sections, once the data source is defined, before we even start extracting the data, we need to know what kind of data we are dealing with and how and where we are going to store it.
Data Model#
A data model is a collection of concepts for describing data, data relationships, data semantics, and consistency constraints. It is a way to describe the data that you are storing in your database.
Example of a Data Model#
In Chip Huyen’s book Designing Machine Learning Systems, she gave an intuitive example on using cars data and features as a data model where you can represent a car by its model (car’s model not the data model), its year, its color and its price. This collection of description is a data model. You can also represent it as a table with its owner’s name, its license plate number and its history. This is also a data model.
Both data models are valid, but the former helps target users who are looking for a car to buy, and the latter helps target users who are looking for a car to rent (i.e. if the history of the car rings any bells).
Data Model |
Focus |
Suitable For |
|---|---|---|
Model 1 |
Car characteristics |
Potential car buyers searching for cars based on preferences |
Model 2 |
Ownership & registration |
Law enforcement agencies tracking down criminals using vehicles |
Relational Model#
A relational model is a data model used to represent and manage data in relational databases. It was first proposed by Edgar F. Codd in 1970 and has since become the foundation for most modern database management systems. The relational model organizes data into tables, also known as relations, which consist of rows and columns.
Each table represents an entity (e.g., a person, a product, or an order), and each row in the table represents an instance or record of that entity. The columns define the attributes or properties of the entity, such as name, age, or price.
The relational model emphasizes the importance of relationships between tables, which are established using primary and foreign keys. A primary key is a unique identifier for each record within a table, while a foreign key is an attribute in one table that refers to the primary key in another table. These keys enable efficient querying and manipulation of data across multiple tables, allowing for complex data retrieval and analysis.
Some key features of the relational model include:
Data integrity: The relational model enforces rules and constraints to maintain the accuracy and consistency of data within the database.
Normalization: Data is organized in a way that minimizes redundancy and ensures efficient storage and retrieval.
ACID (Atomicity, Consistency, Isolation, Durability) properties: Relational databases guarantee transactional integrity, ensuring that data remains consistent and stable even in the event of failures or concurrent access.
SQL (Structured Query Language) is the standard language used to interact with relational databases, allowing users to create, read, update, and delete data within the database.
Normalization#
Chip also mentioned that relational models are just a table with rows as tuples, where tuples hold the record of each row. Relations can be unordered and thus shuffling either the rows or the columns doesn’t change the meaning of the data. CSV and Parquet are both relational models.
The author mentioned that it is desirable for relations to be normalized. We quote a clear example on what it means for normalization and how it reduces data redundancy and improve on data integrity.
Example 45 (Normalization)
Consider the relation Book shown in Table 3-2. There are a lot of duplicates in this data. For example, rows 1 and 2 are nearly identical, except for format and price. If the publisher information changes-for example, its name changes from “Banana Press” to “Pineapple Press”-or its country changes, we’ll have to update rows 1, 2, and 4. If we separate publisher information into its own table, as shown in Tables 3-3 and 3-4, when a publisher’s information changes, we only have to update the Publisher relation. This practice allows us to standardize spelling of the same value across different columns. It also makes it easier to make changes to these values, either because these values change or when you want to translate them into different languages.
Title |
Author |
Format |
Publisher |
Country |
Price |
|---|---|---|---|---|---|
Harry Potter |
J.K. Rowling |
Paperback |
Banana Press |
UK |
$20 |
Harry Potter |
J.K. Rowling |
E-book |
Banana Press |
UK |
$10 |
Sherlock Holmes |
Conan Doyle |
Paperback |
Guava Press |
US |
$30 |
The Hobbit |
J.R.R. Tolkien |
Paperback |
Banana Press |
UK |
$30 |
Sherlock Holmes |
Conan Doyle |
Paperback |
Guava Press |
US |
$15 |
Title |
Author |
Format |
Publisher ID |
Price |
|---|---|---|---|---|
Harry Potter |
J.K. Rowling |
Paperback |
1 |
$20 |
Harry Potter |
J.K. Rowling |
E-book |
1 |
$10 |
Sherlock Holmes |
Conan Doyle |
Paperback |
2 |
$30 |
The Hobbit |
J.R.R. Tolkien |
Paperback |
1 |
$30 |
Sherlock Holmes |
Conan Doyle |
Paperback |
2 |
$15 |
Publisher ID |
Publisher |
Country |
|---|---|---|
1 |
Banana Press |
UK |
2 |
Guava Press |
US |
The downside is now you have 2 tables to maintain, which require you to join them together to get the full picture.
Databases built around this relational concept are called relational databases (e.g. MySQL, PostgreSQL, etc.).
Imperative vs Declarative#
Imperative programming is when you tell the computer what to do step by step and it executes it to get the output. Declarative programming is when you tell the computer what you want and it figures out how to get it. Relational databases are declarative while languages such as Python are imperative.
SQL is inherently declarative. When you write an SQL query, you specify what result you want, not how to achieve it. The database engine decides the best way to execute the query.
SELECT name, age FROM Users WHERE age > 30 ORDER BY age DESC;
If you were to implement the same functionality imperatively, as you might in Python, you would need to write detailed instructions to specify how to filter and sort the data.
from typing import List, Dict, Union
users = [{"name": "Alice", "age": 31}, {"name": "Bob", "age": 25}, {"name": "Carol", "age": 34}]
def get_sorted_users_by_age(users: List[Dict[str, Union[str, int]]]) -> List[Dict[str, Union[str, int]]]:
filtered_users = [user for user in users if user["age"] > 30]
sorted_users = sorted(filtered_users, key=lambda x: x["age"], reverse=True)
return sorted_users
sorted_users = get_sorted_users(users)
NoSQL#
One of the main reason that calls for the need for NoSQL databases is due to relational databases’ strict schema enforcement and is a major pain point for many applications. On the other hand, NoSQL databases generally do not enforce a fixed schema, which means the data structure can evolve as the application’s requirements change. This flexibility is particularly useful for handling unstructured or semi-structured data, such as text, multimedia, or JSON documents.
Document Model#
The document model is a part of NoSQL databases. NoSQL databases encompass various data models, including document, graph, key-value, and column-family stores.
The document model is one such NoSQL data model where data is stored as documents, usually in formats like JSON, XML, or BSON (Binary JSON). The document model provides a flexible and schema-less structure, making it easier to handle diverse or changing data requirements. This flexibility, along with better locality, makes the document model a popular choice for many applications. However, it may not be the best fit for every use case, as performing complex joins or queries can be more difficult and less efficient compared to relational databases.
In summary, the document model is a part of NoSQL databases, which provide alternative data models to address specific needs not effectively met by traditional relational databases.
Built around the concept of “document” |
Documents encoded in formats like JSON, XML, or BSON |
Unique key represents each document |
Collections of documents analogous to tables in relational databases |
Greater flexibility as documents in the same collection can have different schemas |
Better locality than the relational model because all information about a document is stored within a single document, where in a relational model, you might need to perform joins across multiple tables to gather all the information related to a document. |
Examples#
Recall the tables Table 23 and Table 24, we can now convert them into three JSON documents as show below.
Document 1: Title of Harry Potter.
{ "Title": "Harry Potter", "Author": "J.K. Rowling", "Publisher": "Banana Press", "Country": "UK", "SoldAs": [ {"Format": "Paperback", "Price": "$20"}, {"Format": "E-book", "Price": "$10"}, ], }
Document 2: Title of Sherlock Holmes.
{ "Title": "Sherlock Holmes", "Author": "Conan Doyle", "Publisher": "Guava Press", "Country": "US", "SoldAs": [ {"Format": "Paperback", "Price": "$30"}, {"Format": "E-book", "Price": "$15"}, ], }
Document 3: Title of The Hobbit.
{ "Title": "The Hobbit", "Author": "J.R.R. Tolkien", "Publisher": "Banana Press", "Country": "UK", "SoldAs": [{"Format": "Paperback", "Price": "$30"}], }
Advantages#
This format, which represents the data as JSON documents in a document model, can be better for certain use cases due to the following reasons:
Flexibility: Unlike relational databases, the document model allows each document to have a different schema. This means that you can store different attributes for each book without having to modify the structure of the entire database.
Better locality: In the document model, all information about a book is stored within a single document, making it easier to retrieve. In a relational model, you might need to perform joins across multiple tables to gather all the information related to a book, which can be more time-consuming and computationally expensive.
Schema-less: Although the term “schema-less” can be misleading, it signifies that document databases do not enforce a strict schema like relational databases. This allows for more flexibility when dealing with data that does not fit neatly into predefined structures.
Disadvantages#
In the document model, to find all books with prices below \(25, you would have to iterate through each document, examine the `SoldAs` array, and compare the prices to \)25. If the price is below $25, you can return or store the document for further processing.
This approach can be less efficient compared to using a relational model, where you can use a simple SQL query with a WHERE clause to filter the books based on the price condition. The SQL query would be more concise and potentially more efficient in terms of execution time.
However, the trade-offs between the document and relational models depend on the specific use case and data requirements. The document model can be more suitable for applications that require flexibility, better locality, and do not frequently perform complex joins. On the other hand, a relational model can be more appropriate for applications that rely heavily on structured data and require the ability to perform complex queries and joins efficiently.
Graph Model#
The graph model is another type of NoSQL data model that is specifically designed for handling highly interconnected data. In this model, data is represented as nodes (or vertices) and edges, where nodes represent entities and edges represent the relationships between those entities. Graph databases can efficiently model complex relationships and perform traversals, making them ideal for use cases where relationships between data items are common and important.
With all the hype of vector databases nowadays, we see graph databases such as Neo4j to resurface as a popular choice for handling highly interconnected data and build knowledge graphs.
Some key features of graph databases are:
Nodes: Nodes are the primary entities in a graph database, representing objects such as people, products, or locations. Each node can have properties, which are key-value pairs that provide additional information about the node.
Edges: Edges (or relationships) are the connections between nodes, representing various types of relationships between entities. Edges can also have properties, allowing for the storage of additional information about the relationship, such as weights or timestamps.
Graph traversal: One of the main strengths of graph databases is their ability to efficiently perform graph traversal operations. This allows for queries that involve multiple levels of relationships, such as finding the shortest path between two nodes or identifying all nodes within a certain distance of a specific node.
Index-free adjacency: Graph databases use index-free adjacency, meaning that each node directly references its adjacent nodes. This allows for faster traversal operations, as there is no need to perform expensive index lookups to find related nodes.
Schema flexibility: Like other NoSQL databases, graph databases generally offer more flexibility in terms of schema compared to relational databases. This makes it easier to adapt to changing data requirements or evolving relationships between entities.
Some common use cases for graph databases include:
Social networks: Graph databases can efficiently model the relationships between users, such as friends, followers, or interests.
Recommendation systems: By modeling user preferences and item relationships, graph databases can be used to generate personalized recommendations.
Fraud detection: By analyzing relationships and patterns within transactional data, graph databases can help identify suspicious activity.
Knowledge graphs: Graph databases can represent and store complex relationships between entities in a knowledge domain, making it easier to perform advanced queries and infer new information.
Example#
The data from this example could potentially come from a simple social network. In this graph, nodes can be of different data types: person, city, country, company, etc. Imagine you want to find everyone who was born in the USA. Given this graph, you can start from the node USA and traverse the graph following the edges “within” and “born_in” to find all the nodes of the type “person.” Now, imagine that instead of using the graph model to represent this data, we use the relational model. There’d be no easy way to write an SQL query to find everyone who was born in the USA, especially given that there are an unknown number of hops between country and person—there are three hops between Zhenzhong Xu and USA while there are only two hops between Chloe He and USA. Similarly, there’d be no easy way for this type of query with a document database[1].
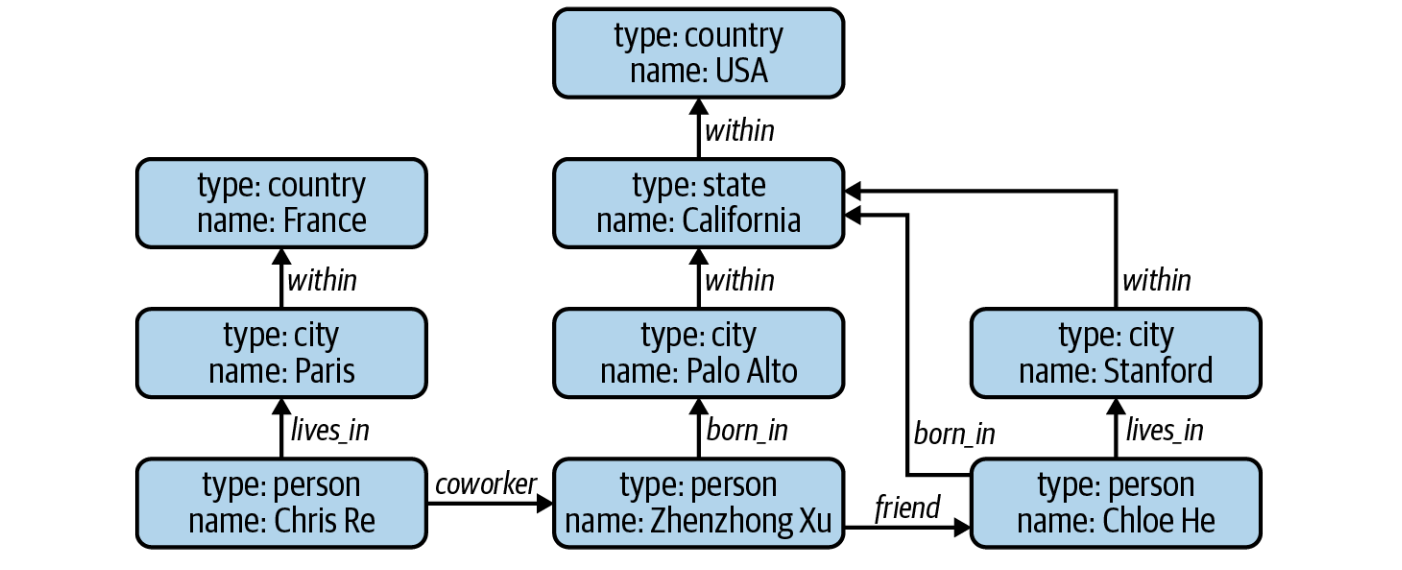
Fig. 47 An example of a simple graph database. Image Credit: Huyen, Chip. Designing Machine Learning Systems: An Iterative Process for Production-Ready Applications, O’Reilly Media, Inc., 2022.#
Structured vs Unstructured Data#
Structured data follows a predefined data model (data schema) and unstructured data does not.
Structured data is easier to query and analyze because you predefine the data schema.
For example, if your data model has two column,
nameandage, wherenameis a string not longer than 100 characters andageis an integer between 0 and 120, then you can safely average theagecolumn without worrying about ifageis a string.The downside is now you are committed to this schema, so if you want to change or add new stuff, you have to retrospecitively update all your past data, causing errors and inconsistencies in the process.
Unstructured data on the other hand can be anything. For example, the logs of your model is a text containing a lot of information, and it is unstructured. Another example is the medical report of a CT scan of patients, which consists of a lot of images and text written by doctors. Those are unstructured data.
One distinction is for structured data, the code that writes the data into the database has to adhere to the schema structure, while for unstructured data, the code that reads the data from the database has to adhere to the schema structure[1]. Writing unstructured data is easy, but when reading you must be very sure of what the data structure is.
Data warehouse is a collection of structured data, while data lake is a collection of unstructured data. Data lakes are usually used to store raw data prior to being processed by data pipelines. Data warehouses are usually used to store processed data for analysis.
Structured Data |
Unstructured Data |
|---|---|
Schema clearly defined |
Data doesn’t have to follow a schema |
Easy to search and analyze |
Fast arrival |
Can only handle data with a specific schema |
Can handle data from any source |
Schema changes will cause a lot of troubles |
No need to worry about schema changes (yet), as the worry is shifted to the downstream applications that use this data |
Stored in data warehouses |
Stored in data lakes |
Structure is assumed at write time |
Structure is assumed at read time |
Data Storage Engines#
Transactional And Analytical Processing Databases#
The concept of transactional and analytical processing databases is hazy to those who are not familiar with the underlying concept of data storage engines. As someone who is not familiar with the concept, one might wonder what’s the difference between the two - for example, if I tell you that PostgreSQL is a transactional processing database, and Amazon Redshift is an analytical processing database, what does that mean? Don’t they both “query” data similarly? Let’s again refer to Chip Huyen’s book Designing Machine Learning Systems for a clear explanation.
Transactional Processing#
Firstly, we understand the idea of transactional processing databases. One who might have done some API development might be familiar with the concept of transactions through the lens of CRUD operations. For example, when a banking customer checks their balance, the operation involves a “read” transaction. This transaction interacts with the database to retrieve the requested information, such as the account balance. And for “create” transactions, when a customer transfers money from one account to another, the operation involves a “write” transaction. This transaction interacts with the database to update the account balances accordingly. This type of processing is what we call online transaction processing (OLTP)[1].
Atomicity, Consistency, Isolation, Durability (ACID)#
As we can see, transactional processing databases are designed to handle user-facing operations that require real-time responses and maintain the integrity of the data. These databases adhere to the ACID properties, which ensure that transactions satisfy crucial operational requirements such as low latency, high availability, and data consistency.
Property |
Description |
|---|---|
Atomicity |
Ensures that a transaction is treated as a single unit of work, either fully completed or fully rolled back in case of failure. As an example, if a user book an uber ride, we might trigger a single transaction but involving several operations such as reading the user’s account balance, deducting the fare, and updating the account balance. If any of these operations fail, the entire transaction fails. I mean if you read the user’s account balance and he has 0 dollars, yet you still deduct the fare, that’s a problem. |
Consistency |
Ensures that the database remains in a consistent state before and after the transaction, maintaining all predefined rules, such as data integrity constraints and business rules. For example, in a bank, a user’s account must not go below zero after a transaction - the no-overdraft rule. |
Isolation |
Ensures that multiple transactions can run concurrently without interfering with each other. For example, if two users try to book the same uber ride at the same time, the system should ensure that each user’s transaction is isolated from the other, and not be assigned the same driver. |
Durability |
Ensures that once a transaction is committed, its changes are permanently stored and cannot be lost, even in the event of a system failure. For example, if a user successfully books an uber ride, the system must ensure that the booking is recorded and cannot be lost due to a power outage or server crash. |
Transactional Databases Are Row-Major#
Traditional transactional databases are row-major, meaning that they are optimized for reading and writing individual rows of data. This design is well-suited for handling OLTP workloads, where transactions typically involve small, granular operations on individual records. However, when it comes to analyzing large volumes of data or running complex queries that involve aggregations, joins, and filtering, row-major databases may not be the most efficient choice. For example, if you want to calculate the average age of all users in a database, a row-major database would need to scan through every row to compute the result, which can be slow and resource-intensive. This is where analytical processing databases come into play.
Analytical Processing#
Analytical processing databases are designed to handle complex queries that involve aggregations, joins, and filtering on large datasets. These databases are usually multi-dimensional and are very efficient. We denote this type of processing as online analytical processing (OLAP)[1].
However, modern databases can handle both transactional and analytical workloads (i.e. CockroachDB, Amazon Iceberg, etc.).
Data Lake, Data Warehouse, Data Lakehouse, Delta Lake#
Type |
Definition |
Examples |
|---|---|---|
Data Lake |
A centralized repository that allows you to store all your structured and unstructured data at any scale, in its native format, without requiring a predefined schema. |
Amazon S3, Azure Data Lake Storage |
Data Warehouse |
A system used for reporting and data analysis, acting as a central repository of integrated data from one or more disparate sources, structured for easy access and analysis. |
Amazon Redshift, Google BigQuery, Snowflake |
Data Lakehouse |
Combines features of data lakes and data warehouses, supporting both BI and machine learning on a single platform, with low-cost storage and schema enforcement. |
Databricks Lakehouse, Delta Lake on Databricks |
Delta Lake |
An open-source storage layer that brings reliability to data lakes, providing ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. |
Works with Apache Spark, Amazon S3, Azure Data Lake Storage |
Vector Database (A High-dimensional Playground for Large Language Models)#
A vector database is like a database which is a data storage system that capitalizes on the properties of vectors embeddings. The high-dimensional vectors stored in these databases embody the features or attributes of data, which could range from text, images, audio, and video to even more complex structures. We can have additional metadata to describe the data, but the vectors are the main focus.
The crucial task of converting raw data to their vector representations (embeddings) is typically achieved by utilizing machine learning models, word embedding algorithms, or feature extraction techniques.
For instance, a movie review text can be represented as a high-dimensional vector via transformer based embedding models. Similarly, an image can be transformed into a vector representation using deep learning models like convolutional neural networks (CNNs).
Vector databases deviate from the conventional way databases work. Rather than retrieving data based on exact matches or predefined criteria, vector databases empower users to conduct searches based on vector similarity. This facilitates the retrieval of data that bears semantic or contextual similarity to the query data, even if they don’t share exact keyword matches.
Consider this example: Given an image of a cat, a vector database can find images that are visually similar (e.g., other images of cats, or perhaps images of small, furry animals), even if “cat” isn’t explicitly tagged or described in the metadata of those images via the vector representations.
See Also
There are much more to vector databases than what we have covered here. For a detailed survey on vector databases, you can refer to the following series of articles:
References and Further Readings#
Huyen, Chip. “Chapter 3. Data Engineering Fundamentals.” In Designing Machine Learning Systems: An Iterative Process for Production-Ready Applications, O’Reilly Media, Inc., 2022.
Kleppmann, Martin. “Chapter 2. Data Models and Query Languages.” In Designing Data-Intensive Applications. Beijing: O’Reilly, 2017.